
Cofinder
Cofinder
This project was created by community member Elle Neal.
Introduction
Cofinder is designed to help the Cohere Community find relevant content in one place based on their personal goals. With Cofinder, users can ask natural language questions, and the tool will provide the most relevant content, aim to answer their questions, and provide context.
Cofinder is the result of my desire to make it easier for the Cohere community to access the wealth of knowledge and resources available on the platform. While Cohere provides an incredible variety of resources, such as product explanations, tutorials, open repositories, and a Discord channel, I recognised that finding specific information can still be time-consuming and inefficient. The dataset behind Cofinder is text extracted from these sources. By creating a semantic search tool that brings together information from multiple sources, Cofinder aims to streamline the process and save users valuable time. The goal is to enhance the Cohere community experience by making it easy for developers, entrepreneurs, corporations, and data scientists to find what they need in one place.
Repository Contents
cohere_text_preprocessing.csv: contains text prior to pre-processingpreprocessing.ipynb: this contains our code for generating embeddings and preparing our search index using thecohere_text_preprocessing.csvfilemain.py: this contains our code for the Streamlit app
These files will be produced when you run preprocessing.ipynb
cohere_text_final.csv: text after pre-processingsearch_index.ann: a search index containing our embeddings
Five Steps to Building the Application
We can breakdown the process into 5 steps of development:
- Data Sources: pre-processing the article text into chunks.
- Embeddings & Search Index: use co.embed to obtain a vector representation of our data. Store your embeddings in a vector database which we will later use to search for relevant content.
- Front End: Streamlit for our user to interact with our search engine.
- Search: we use co.embed to get the vector representation of the user query, using nearest neighbours to return relevant content.
- Answer: use co.generate to answer the query given the context from the search results and the question.
Step 1: Data Sources — Pre-processing Text
The repository contains a csv file called cohere_text_preprocessing.csv with a row for each url, the title and the text taken from the webpage. Each item contains a category and type which is returned in the search results.
After importing the csv file, we need to pre-process the text into chunks, the chunks will be used in a later stage as context where we want to generate an answer. As we will use co.generate for this task, we need to make sure our text chunks are no larger than 1500 words.
To maintain context, we will split the text chunks into 1500 and overlap the chunks using 500 tokens from the previous chunk relevant to the article.
import textwrap
def chunk_text(df, width=1500, overlap=500):
# create an empty dataframe to store the chunked text
new_df = pd.DataFrame(columns=['id', 'text_chunk'])
# iterate over each row in the original dataframe
for index, row in df.iterrows():
# split text into chunks of size 'width', with overlap of 'overlap'
chunks = []
for i in range(0, len(row['text']), width - overlap):
chunk = row['text'][i:i+width]
chunks.append(chunk)
# iterate over each chunk and add it to the new dataframe
for i, chunk in enumerate(chunks):
# calculate the start index based on the chunk index and overlap
start_index = i * (width - overlap)
# create a new row with the chunked text and the original row's ID
new_row = {
'id': row['id'],
'text_chunk': chunk,
'start_index': start_index}
new_df = new_df.append(new_row, ignore_index=True)
return new_df
# run the function on the dataframe
new_df = chunk_text(df)
Step 2a: Get embeddings
We use the co.embed endpoint to obtain a vector representation of our data.
import cohere
import numpy as np
co = cohere.Client('<API_KEY>')
# Get the embeddings
embeds = co.embed(texts=list(df['text_chunk']),
model="large",
truncate="RIGHT").embeddings
# Check the dimensions of the embeddings
embeds = np.array(embeds)
embeds.shape
Great! We now have our pre-processed text and embeddings ready for the next stage where we create a search index to store the data.
Step 2b: Search Index
We now create a search index using Annoy to store the embeddings.
from annoy import AnnoyIndex
# Create the search index, pass the size of embedding
search_index = AnnoyIndex(embeds.shape[1], 'angular')
# Add all the vectors to the search index
for i in range(len(embeds)):
search_index.add_item(i, embeds[i])
search_index.build(10) # 10 trees
search_index.save('search_index.ann')
The final three stages are to create our Streamlit application, we load the relevant libraries, data and search index from the previous stages. We then add functions to generate embeddings to search the Annoy index for the user’s query, and generate an answer from the context. This is all tied together in the Streamlit app with widgets for user input and markdown to display the results.
This section of code can be found in main.py
Step 3: Front End — Streamlit
In the main.py file, we build our code for the Streamlit application.
Here we import the libraries we need, the API key, initiate our cohere client and load the search index and csv file.
import streamlit as st
import cohere
import numpy as np
import pandas as pd
from annoy import AnnoyIndex
from concurrent.futures import ThreadPoolExecutor
import toml
# Load the secret.toml file
with open('secret.toml') as f:
secrets = toml.load(f)
# Access the API key value
api_key = secrets['API_KEY']
co = cohere.Client('api_key')
# Load the search index
search_index = AnnoyIndex(f=4096, metric='angular')
search_index.load('search_index.ann')
# load the csv file called cohere_final.csv
df = pd.read_csv('cohere_text_final.csv')
# title
st.title("Cofinder")
st.subheader("A semantic search tool built for the Cohere community")
Step 4: Search Function
The search function takes in a query, the number of search results to return n_results, a dataframe df, an index search_index, and an embedding model co.embed(). Here's a step-by-step breakdown of what the function does:
- The function uses the
co.embedfunction to get the embedding of the query using the specified model ("large"). - The function uses the
search_index.get_nns_by_vectorfunction to get then_resultsnearest neighbors to the query embedding in the specified indexsearch_index. The function returns the indices of the nearest neighbors as well as the similarity scores. - The function filters the original dataframe (
df) to include only the rows that correspond to the nearest neighbors returned in step 2. - The function adds two new columns to the filtered dataframe: similarity, which contains the
similarityscores between the query embedding and the document embeddings; andnearest_neighbors, which contains the indices of the nearest neighbors. - Finally, the function sorts the filtered dataframe by similarity in descending order and returns it.
The results of the search will be used as context to answer the user’s question.
def search(query, n_results, df, search_index, co):
# Get the query's embedding
query_embed = co.embed(texts=[query],
model="large",
truncate="LEFT").embeddings
# Get the nearest neighbors and similarity score for the query
# and the embeddings, append it to the dataframe
nearest_neighbors = search_index.get_nns_by_vector(
query_embed[0],
n_results,
include_distances=True)
# filter the dataframe to include the nearest neighbors using the index
df = df[df.index.isin(nearest_neighbors[0])]
df['similarity'] = nearest_neighbors[1]
df['nearest_neighbors'] = nearest_neighbors[0]
df = df.sort_values(by='similarity', ascending=False)
return df
When we run this function, we get a JSON output containing the article title and the context relevant to the query
Question: How do I use Cohere to build a chatbot?
[
0:[
0:" Use Cohere's Classify endpoint for intent recognition and text classification."
1:"Paragraph:Use Cohere’s Classify for intent recognition and text classification. Starting from the same Transformer architecture as Google’s Search and Translate, Cohere’s Classify endpoint can read, understand, and label the intent behind unstructured customer queries with exceptional speed and accuracy. Developers can further finetune Cohere’s large language models with their own dataset per their business or industry. Set the road rules, define your core customer intent categories, and train Cohere’s Classify model by providing it with example customer queries for each category. Start the engine, Classify then combines this custom understanding of your intent categories with a deep understanding of language and context provided by our large language models to create a finetuned model, ready to handle your customer data. Get driving, every time a user enters a prompt into your chatbot, Cohere will classify the request by intent, allowing your bot to provide the most relevant answer back. Answer the question using this paragraph. Question: How do I use Cohere to build a chatbot? Answer:"
]
1:[
0:" Cohere uses billions of examples to train their models, which allows them to understand and recognize the intent behind a specific phrase. This intent recognition is used to power sophisticated chatbots that move beyond basic keyword recognition."
1:"Paragraph:Billions of examples, Cohere’s models are trained on billions of sentences, allowing them to understand and recognize the intent behind a specific phrase. Our models excel at intent recognition tasks and can power sophisticated chatbots that move beyond basic keyword recognition. Answer the question using this paragraph. Question: How do I use Cohere to build a chatbot? Answer:"
]
2:[
0:" Cohere is a chatbot platform that is powered by basic keyword recognition. This means that the bot's ability to 'understand' queries is dependent upon customers using very specific phrases."
1:"Paragraph:Keywords aren’t enough. Many chatbot platforms are powered by basic keyword recognition. This means that the bot’s ability to “understand” queries is dependent upon customers using very specific phrases. Developers could augment this by painstakingly predicting the myriad ways that a customer could phrase a specific query, including slang, misspellings, and differences in context. However, that task would be time consuming, if not downright impossible Answer the question using this paragraph. Question: How do I use Cohere to build a chatbot? Answer:"
]
3:[
0:" "Cohere's API is created to help you build natural language understanding and generation into your production with a few lines of code. Our Quickstart Tutorials will show you how to implement our API from zero-to-one in under 5 minutes.""
1:"Paragraph:["Cohere's API is created to help you build natural language understanding and generation into your production with a few lines of code. Our Quickstart Tutorials will show you how to implement our API from zero-to-one in under 5 minutes. ", 'Chatbots are designed to understand and respond to human language. They need to be able to understand the text they hear and understand the context of the conversation. They also need to be able to respond to people’s questions and comments in a meaningful way. To accomplish this, chatbots must be able to recognize specific intents that people express in conversation.Here is an example of classifying the intent of customer inquiries on an eCommerce website into three categories: Shipping and handling policy, Start return or exchange, or Track order.', 'Updated about 1 month ago '] Answer the question using this paragraph. Question: How do I use Cohere to build a chatbot? Answer:"
]
4:[
0:" Our product is a Web based Application which improves the efficiency of chat based support systems by automating repetitive parts of the workflow. This is done by utilising Cohere's API in order to provide smart shortcuts for the Chat Support Agents."
1:"Paragraph:Our product is a Web based Application which improves the efficiency of chat based support systems by automating repetitive parts of the workflow. This is done by utilising Cohere’s API in order to provide smart shortcuts for the Chat Support Agents. We aim to maximise Customer and Customer Support Agent satisfaction by making the lookup of product and service related answers instantaneous, thereby allowing the Customer Support Agent to put more effort into the interaction with the customer rather than the mundane task of researching answers. Answer the question using this paragraph. Question: How do I use Cohere to build a chatbot? Answer:"
]
]
Step 5: Answer Function
We now want to take the user question and generate an answer to the question given the search results from the previous function.
Overall, the display function below is broken down into two tasks,
- The
gen_answerandgen_better_answerfunctions are used to generate answers for the query and each of the search results. Thegen_answerfunction generates an initial answer based on a prompt that includes the paragraph and the question, whilegen_better_answergenerates a better answer by incorporating the initial answers and the question. - The results are displayed in a user-friendly format using the
stmodule from the Streamlit library. The search query is displayed as a subheader, followed by the better answer generated bygen_better_answer. The relevant documents are then displayed, one by one. Each document is displayed with its type, category, title, and link, followed by the initial answer generated bygen_answer. The text of the document is then collapsed and can be expanded by clicking on "Read more".
def display(query, results):
# 1. Run co.generate functions to generate answers
# for each row in the dataframe, generate an answer concurrently
with ThreadPoolExecutor(max_workers=1) as executor:
results['answer'] = list(executor.map(gen_answer,
[query]*len(results),
results['text']))
answers = results['answer'].tolist()
# run the function to generate a better answer
answ = gen_better_answer(query, answers)
# 2. Display the resuls in a user-friendly format
st.subheader(query)
st.write(answ)
# add a spacer
st.write('')
st.write('')
st.subheader("Relevant documents")
# display the results
for i, row in results.iterrows():
# display the 'Category' outlined
st.markdown(f'**{row["Type"]}**')
st.markdown(f'**{row["Category"]}**')
st.markdown(f'{row["title"]}')
# display the url as a hyperlink
# add a button to open the url in a new tab
st.markdown(f'[{row["link"]}]({row["link"]})')
st.write(row['answer'])
# collapse the text
with st.expander('Read more'):
st.write(row['text'])
st.write('')
Let’s explore the the gen_answer and gen_better_answer functions to see what is happening.
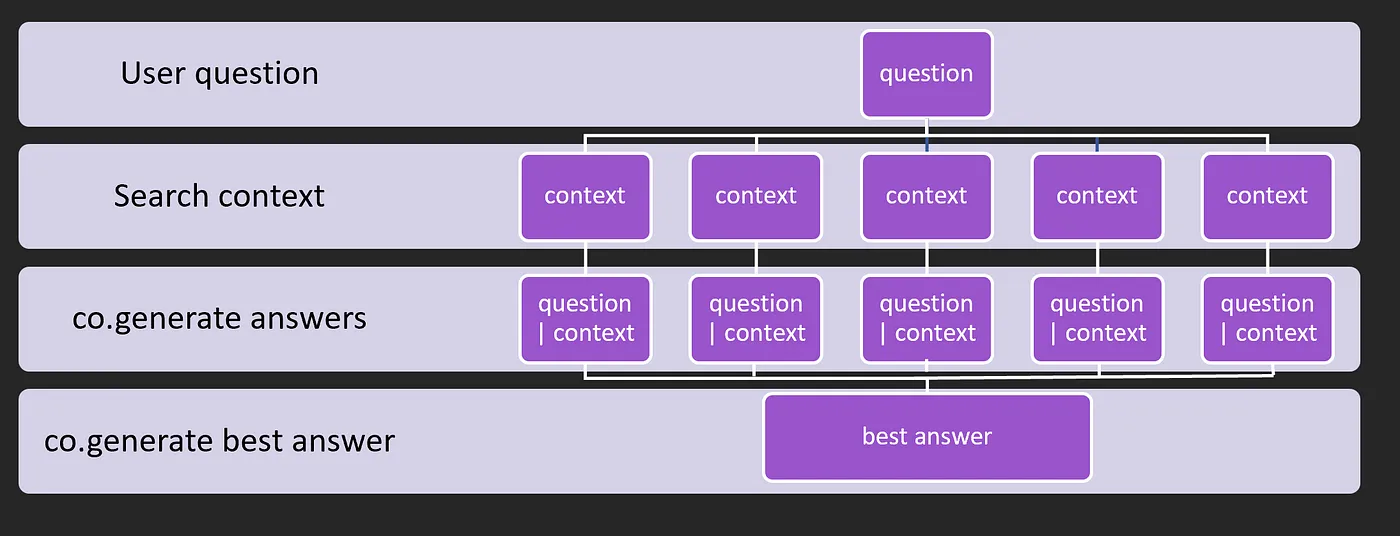
Here we create two co.generate() prompts, these functions use Cohere’s pre-trained models to generate text that answers a given question from the context provided from the search results.
gen_answer(q, para): This function returns an answer to the question given the context returned from our search function. In the display function above, we ran this function by iterating over each of the search results from the JSON output to gather context from multiple sources.gen_better_answer(ques, ans): This function takes the question and all of the responses from thegen_answerfunction, it uses the combined answers to formulate a more rounded answer taking into account all the available resources.
The max_tokens and temperature parameters can be tuned to control the length and randomness of the generated text.
# define a function to generate an answer
def gen_answer(q, para):
response = co.generate(
model='command-xlarge-20221108',
prompt=f'''Paragraph:{para}\n\n
Answer the question using this paragraph.\n\n
Question: {q}\nAnswer:''',
max_tokens=100,
temperature=0.4)
return response.generations[0].text
def gen_better_answer(ques, ans):
response = co.generate(
model='command-xlarge-20221108',
prompt=f'''Answers:{ans}\n\n
Question: {ques}\n\n
Generate a new answer that uses the best answers
and makes reference to the question.''',
max_tokens=100,
temperature=0.4)
return response.generations[0].text
Finally, we add a streamlit search input along with some question examples for the user, and button that runs our functions.
# add the if statements to run the search function when the user clicks the buttons
query = st.text_input('Ask a question about Cohere')
# write some examples to help the user
st.markdown('''Try some of these examples:
- What is the Cohere API?
- What are embeddings?
- What is the Cohere playground?
- How can I build a chatbot?''')
if st.button('Search'):
results = search(query, 3, df, search_index, co)
display(query, results)
Well done! You are now ready to publish your Streamlit application to the cloud!