How to Start with the Cohere Toolkit
Cohere Toolkit is a collection of pre-built components enabling developers to quickly build and deploy retrieval augmented generation (RAG) applications. With it, you can cut time-to-launch down from months to weeks, and deploy in as little as a few minutes.
The pre-built components fall into two big categories: front-end and back end.
- Front-end: The Cohere Toolkit front end is a web application built in Next.js. It includes a simple SQL database out of the box to store conversation history, documents, and citations, directly in the app.
- Back-end: The Cohere Toolkit back-end contains the preconfigured data sources and retrieval code needed to set up RAG on custom data sources, which are called “retrieval chains”). Users can also configure which model to use, selecting from Cohere models hosted on our native platform, Azure, or AWS Sagemaker. By default, we have configured a Langchain data retriever to test RAG on Wikipedia and your own uploaded documents.
Here’s an image that shows how these different components work together:
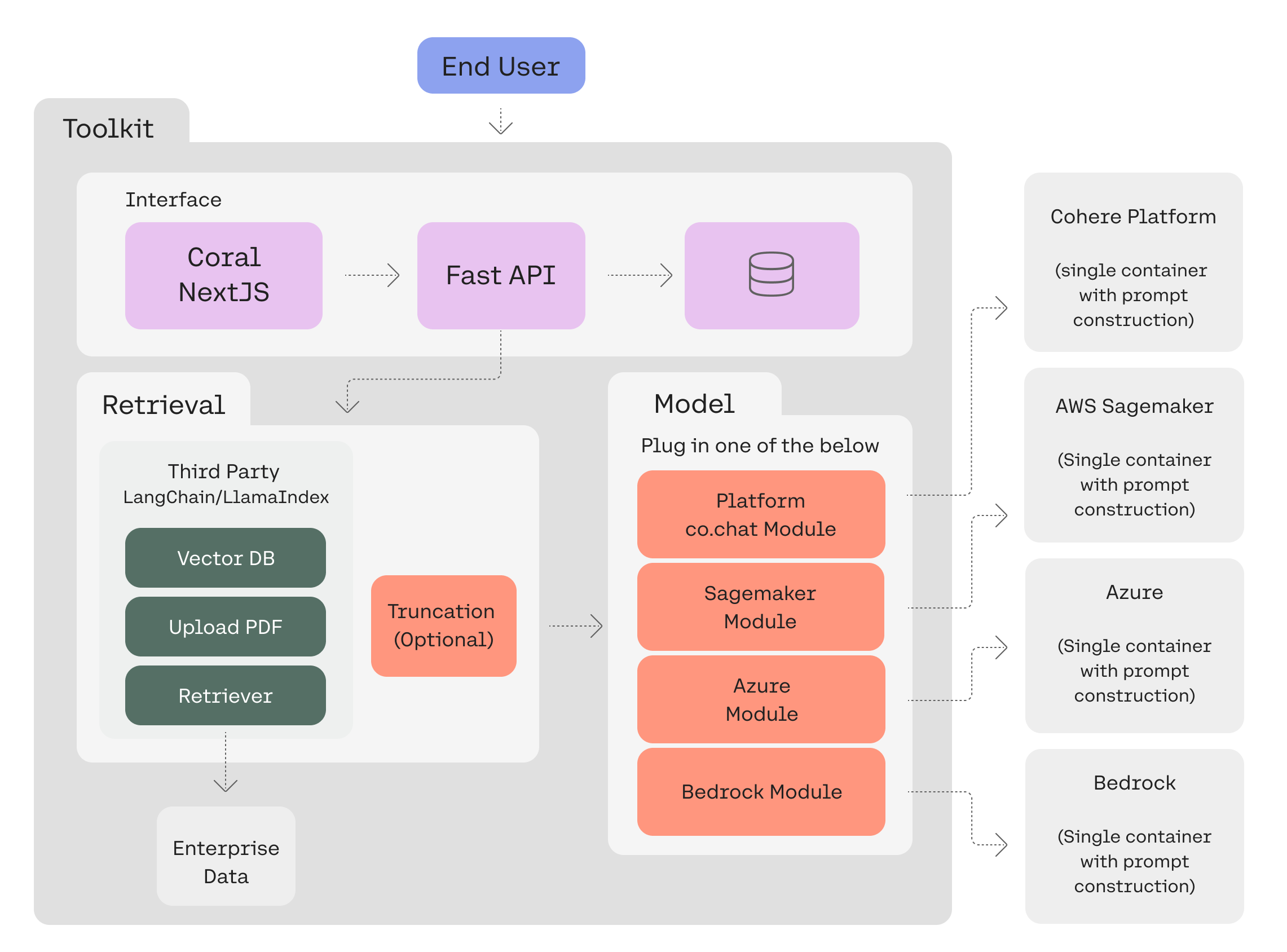
Cohere Toolkit Quick Start
You can get started quickly with toolkit on Google Cloud Run, Microsoft Azure, or locally. Read this for more details, including CLI commands to run after cloning the repo and environment variables that need to be set.
Deploying Cohere Toolkit
The toolkit can be deployed on single containers, AWS ECS, and GCP. Find out how here.
Developing on Cohere Toolkit
If you want to configure old retrieval chains or add new ones, you’ll need to work through a few steps. These include installing poetry, setting up your local database, testing, etc. More context is available here.
Working with Cohere Toolkit
The toolkit is powerful and flexible. There’s a lot you can do with it, including adding your own model deployment, calling the toolkit’s backend over the API, adding a connector, and much else besides.
Following the links in this document or read the full repository to find everything you need!