Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG) is a method for generating text using additional information fetched from an external data source, which can greatly increase the accuracy of the response. When used in conjunction with Command A+, Command A, or Command R7B, the Chat API makes it easy to generate text that is grounded on supplementary information.
The code snippet below, for example, will produce a grounded answer to "Where do the tallest penguins live?", along with inline citations based on the provided documents.
Request
Response
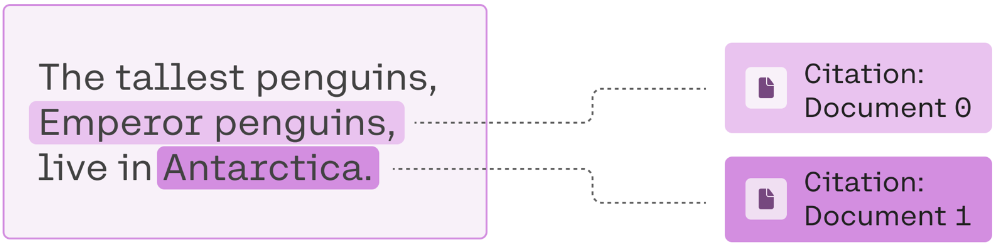
The resulting generation is"The tallest penguins, Emperor penguins, live in Antarctica". The model was able to combine partial information from multiple sources and ignore irrelevant documents to arrive at the full answer.
Nice 🐧❄️!
The response also includes inline citations that reference the first two documents, since they hold the answers.
As you will learn in the following section, the Chat API will also assist you with generating search queries to fetch documents from a data source.
You can find more code and context in this colab notebook.
Three steps of RAG
The RAG workflow generally consists of 3 steps:
- Generating search queries for finding relevant documents. What does the model recommend looking up before answering this question?
- Fetching relevant documents from an external data source using the generated search queries. Performing a search to find some relevant information.
- Generating a response with inline citations using the fetched documents. Using the acquired knowledge to produce an educated answer.
Example: Using RAG to identify the definitive 90s boy band
In this section, we will use the three step RAG workflow to finally settle the score between the notorious boy bands Backstreet Boys and NSYNC. We ask the model to provide an informed answer to the question "Who is more popular: Nsync or Backstreet Boys?"
Step 1: Generating search queries
Option 1: Using the search_queries_only parameter
Calling the Chat API with the search_queries_only parameter set to True will return a list of search queries. In the example below, we ask the model to suggest some search queries that would be useful when answering the question.
Request
Response
Indeed, to generate a factually accurate answer to the question "Who is more popular: Nsync or Backstreet Boys?", looking up Nsync popularity and Backstreet Boys popularity first would be helpful.
Option 2: Using a tool
If you are looking for greater control over how search queries are generated, you can use Cohere’s Tools capabilities to generate search queries
Here, we build a tool that takes a user query and returns a list of relevant document snippets for that query. The tool can generate zero, one or multiple search queries depending on the user query.
You can then customize the preamble and/or the tool definition to generate queries that are more relevant to your use case.
For example, you can customize the preamble to encourage a longer list of search queries to be generated.
Step 2: Fetching relevant documents
The next step is to fetch documents from the relevant data source using the generated search queries. For example, to answer the question about the two pop sensations NSYNC and Backstreet Boys, one might want to use an API from a web search engine, and fetch the contents of the websites listed at the top of the search results.
We won’t go into details of fetching data in this guide, since it’s very specific to the search API you’re querying. However we should mention that breaking up long documents into smaller ones first (1-2 paragraphs) will help you not go over the context limit. When trying to stay within the context length limit, you might need to omit some of the documents from the request. To make sure that only the least relevant documents are omitted, we recommend using the Rerank endpoint endpoint which will sort the documents by relevancy to the query. The lowest ranked documents are the ones you should consider dropping first.
Step 3: Generating a response
In the final step, we will be calling the Chat API again, but this time passing along the documents you acquired in Step 2. A document object is a dictionary containing the content and the metadata of the text. We recommend using a few descriptive keys such as "title", "snippet", or "last updated" and only including semantically relevant data. The keys and the values will be formatted into the prompt and passed to the model.
Request
Response
Not only will we discover that the Backstreet Boys were the more popular band, but the model can also Tell Me Why, by providing details supported by citations.
Connectors
As an alternative to manually implementing the 3 step workflow, the Chat API offers a 1-line solution for RAG using Connectors. In the example below, specifying the web-search connector will generate search queries, use them to conduct an internet search and use the results to inform the model and produce an answer.
Request
Response
In addition to the Cohere provided web-search Connector, you can register your own custom Connectors such as Google Drive, Confluence etc.
Prompt Truncation
LLMs come with limitations; specifically, they can only handle so much text as input. This means that you will often need to figure out which document sections and chat history elements to keep, and which ones to omit.
For more information, check out our dedicated doc on prompt truncation.
Citation modes
When using Retrieval Augmented Generation (RAG) in streaming mode, it’s possible to configure how citations are generated and presented. You can choose between fast citations or accurate citations, depending on your latency and precision needs:
-
Accurate citations: The model produces its answer first, and then, after the entire response is generated, it provides citations that map to specific segments of the response text. This approach may incur slightly higher latency, but it ensures the citation indices are more precisely aligned with the final text segments of the model’s answer. This is the default option, though you can explicitly specify it by adding the
citation_quality="accurate"argument in the API call. -
Fast citations: The model generates citations inline, as the response is being produced. In streaming mode, you will see citations injected at the exact moment the model uses a particular piece of external context. This approach provides immediate traceability at the expense of slightly less precision in citation relevance. You can specify it by adding the
citation_quality="fast"argument in the API call.
Below are example code snippets demonstrating both approaches.
Accurate citations
Example response:
Fast citations
Example response:
Caveats
It’s worth underscoring that RAG does not guarantee accuracy. It involves giving a model context which informs its replies, but if the provided documents are themselves out-of-date, inaccurate, or biased, whatever the model generates might be as well. What’s more, RAG doesn’t guarantee that a model won’t hallucinate. It greatly reduces the risk, but doesn’t necessarily eliminate it altogether. This is why we put an emphasis on including inline citations, which allow users to verify the information.