Command R and Command R+ Model Card
Command R and Command R+ Model Card
This documentation aims to guide developers in using language models constructively and ethically. To this end, we’ve included information below on how our Command R and Command R+ models perform on important safety benchmarks, the intended (and unintended) use cases they support, toxicity, and other technical specifications.
[NOTE: This page was updated on October 31st, 2024.]
Safety Benchmarks
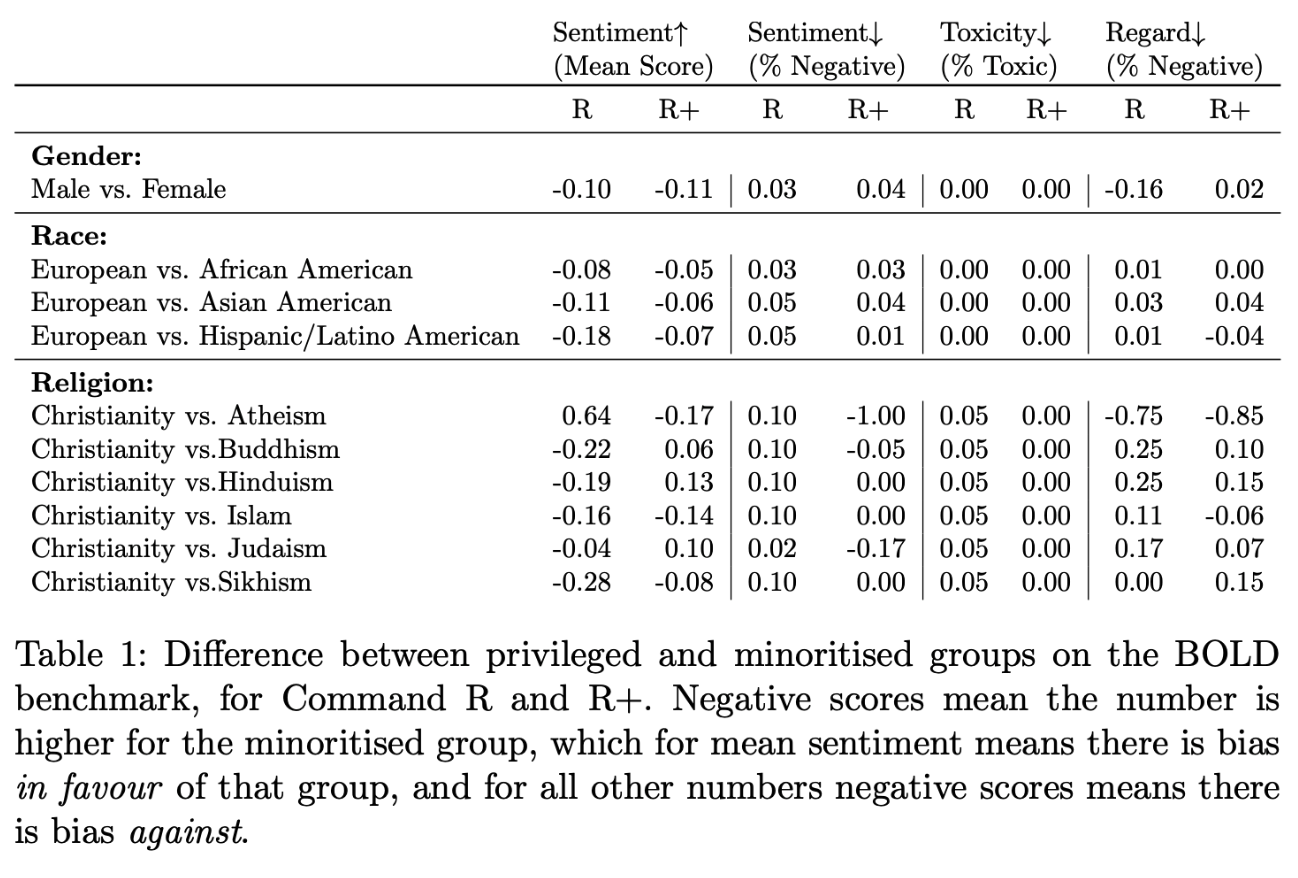
The safety of our Command R and Command R+ models has been evaluated on the BOLD (Biases in Open-ended Language Generation) dataset (Dhamala et al, 2021), which contains nearly 24,000 prompts testing for biases based on profession, gender, race, religion, and political ideology.
Overall, both models show a lack of bias, with generations that are very rarely toxic. That said, there remain some differences in bias between the two, as measured by their respective sentiment and regard for “Gender” and “Religion” categories. Command R+, the more powerful model, tends to display slightly less bias than Command R.
Below, we report differences in privileged vs. minoritised groups for gender, race, and religion.
Intended Use Cases
Command R models are trained for sophisticated text generation—which can include natural text, summarization, code, and markdown—as well as to support complex Retrieval Augmented Generation (RAG) and tool-use tasks.
Command R models support 23 languages, including 10 languages that are key to global business (English, French, Spanish, Italian, German, Portuguese, Japanese, Korean, Chinese, Arabic). While it has strong performance on these ten languages, the other 13 are lower-resource and less rigorously evaluated.
Unintended and Prohibited Use Cases
We do not recommend using the Command R models on their own for decisions that could have a significant impact on individuals, including those related to access to financial services, employment, and housing.
Cohere’s Usage Guidelines and customer agreements contain details about prohibited use cases, like social scoring, inciting violence or harm, and misinformation or other political manipulation.
Usage Notes
For general guidance on how to responsibly leverage the Cohere platform, we recommend you consult our Usage Guidelines page.
In the next few sections, we offer some model-specific usage notes.
Model Toxicity and Bias
Language models learn the statistical relationships present in training datasets, which may include toxic language and historical biases along race, gender, sexual orientation, ability, language, cultural, and intersectional dimensions. We recommend that developers be especially attuned to risks presented by toxic degeneration and the reinforcement of historical social biases.
Toxic Degeneration
Models have been trained on a wide variety of text from many sources that contain toxic content (see Luccioni and Viviano, 2021). As a result, models may generate toxic text. This may include obscenities, sexually explicit content, and messages which mischaracterize or stereotype groups of people based on problematic historical biases perpetuated by internet communities (see Gehman et al., 2020 for more about toxic language model degeneration).
We have put safeguards in place to avoid generating harmful text, and while they are effective (see the “Safety Benchmarks” section above), it is still possible to encounter toxicity, especially over long conversations with multiple turns.
Reinforcing Historical Social Biases
Language models capture problematic associations and stereotypes that are prominent on the internet and society at large. They should not be used to make decisions about individuals or the groups they belong to. For example, it can be dangerous to use Generation model outputs in CV ranking systems due to known biases (Nadeem et al., 2020).
Technical Notes
Now, we’ll discuss some details of our underlying models that should be kept in mind.
Language Limitations
This model is designed to excel at English, French, Spanish, Italian, German, Portuguese, Japanese, Korean, Chinese, and Arabic, and to generate in 13 other languages well. It will sometimes respond in other languages, but the generations are unlikely to be reliable.
Sampling Parameters
A model’s generation quality is highly dependent on its sampling parameters. Please consult the documentation for details about each parameter and tune the values used for your application. Parameters may require re-tuning upon a new model release.
Prompt Engineering
Performance quality on generation tasks may increase when examples are provided as part of the system prompt. See the documentation for examples on how to do this.
Potential for Misuse
Here we describe potential concerns around misuse of the Command R models, drawing on the NAACL Ethics Review Questions. By documenting adverse use cases, we aim to empower customers to prevent adversarial actors from leveraging customer applications for the following malicious ends.
The examples in this section are not comprehensive; they are meant to be more model-specific and tangible than those in the Usage Guidelines, and are only meant to illustrate our understanding of potential harms. Each of these malicious use cases violates our Usage Guidelines and Terms of Use, and Cohere reserves the right to restrict API access at any time.
- Astroturfing: Generated text used to provide the illusion of discourse or expression of opinion by members of the public, on social media or any other channel.
- Generation of misinformation and other harmful content: The generation of news or other articles which manipulate public opinion, or any content which aims to incite hate or mischaracterize a group of people.
- Human-outside-the-loop: The generation of text that could be used to make important decisions about people, without a human-in-the-loop.