The Embed Endpoint
 In Module 1 you learned about text embeddings, and how they are a very useful way to turn text into numbers that capture its meaning and context. In this chapter you’ll learn how to put them in practice using the Embed endpoint. You’ll use it to explore a dataset of sentences, and be able to plot them in the plane and observe graphically that indeed similar sentences are mapped to close points in the embedding.
In Module 1 you learned about text embeddings, and how they are a very useful way to turn text into numbers that capture its meaning and context. In this chapter you’ll learn how to put them in practice using the Embed endpoint. You’ll use it to explore a dataset of sentences, and be able to plot them in the plane and observe graphically that indeed similar sentences are mapped to close points in the embedding.
Colab Notebook
This chapter comes with a corresponding notebook, and we encourage you to follow it along as you read the chapter.
For the setup, please refer to the Setting Up chapter at the beginning of this module.
Semantic Exploration
The dataset we’ll use is formed of 50 top search terms on the web about “Hello, World!”.
The following are a few examples:
Here’s how to use the Embed endpoint:
-
Prepare input — The input is the list of text you want to embed.
-
Define model type — At the time of writing, there are three models available:
embed-english-v3.0(English)embed-english-light-v3.0(English)embed-multilingual-v3.0(Multilingual: 100+ languages)embed-multilingual-light-v3.0(Multilingual: 100+ languages)
We’ll use
embed-english-v3.0for our example. -
Generate output — The output is the corresponding embeddings for the input text.
The code looks like this:
For every piece of text passed to the Embed endpoint, a sequence of numbers will be generated. Each number represents a piece of information about the meaning contained in that piece of text.
Note that we defined a parameter input_type with search_document as the value. There are several options available, which you must choose according to the type of document to be embedded:
search_document: Use this for the documents against which search is performed.search_query: Use this for the query document.classification: Use this when you use the embeddings as an input to a text classifier.clustering: Use this when you want to cluster the embeddings.
To understand what these numbers represent, there are techniques we can use to compress the embeddings down to just two dimensions while retaining as much information as possible. And once we can get it down to two dimensions, we can plot these embeddings on a 2D plot.
We can make use of the UMAP technique to do this. The code is as follows:
You can then use any plotting library to visualize these compressed embeddings on a 2D plot.
Here is the plot showing all 50 data points:

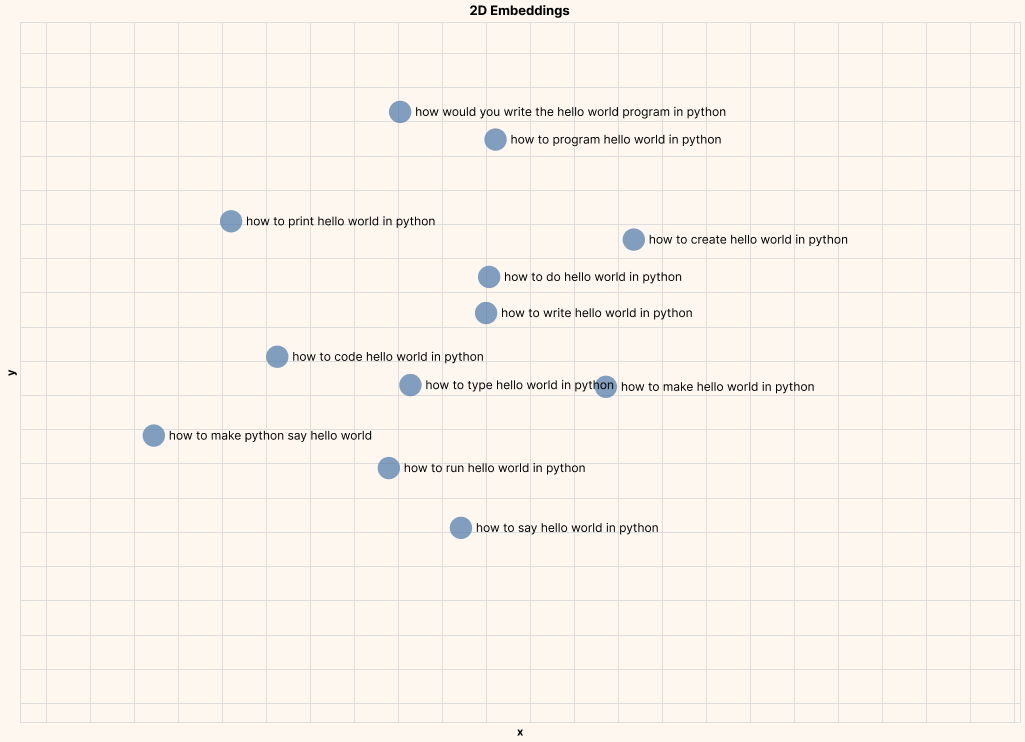
And here are a few zoomed-in plots, clearly showing text of similar meaning being closer to each other.
Example #1: Hello, World! In Python
Example #2: Origins of Hello, World!

These kinds of insights enable various downstream analyses and applications, such as topic modeling, by clustering documents into groups. In other words, text embeddings allow us to take a huge corpus of unstructured text and turn it into a structured form, making it possible to objectively compare, dissect, and derive insights from all that text.
In the coming chapters, we’ll dive deeper into these topics.
Conclusion
In this chapter you learned about the Embed endpoint. Text embeddings make possible a wide array of downstream applications such as semantic search, clustering, and classification. You’ll learn more about those in the subsequent chapters.
Original Source
This material comes from the post Hello, World! Meet Language AI: Part 2