Starting the Chat Fine-Tuning Run
Starting the Chat Fine-Tuning Run
Cohere’s fine-tuning feature was deprecated on September 15, 2025
In this section, we will walk through how you can start training a fine-tuning model for Chat on both the Web UI and the Python SDK.
Cohere Dashboard
Fine-tuning of the Command family of models for Chat with the Web UI consists of a few simple steps, which we’ll walk through now.
Choose the Chat Option
Go to the fine-tuning page and click on ‘Create a Chat model’.
Upload Your Data
Upload your custom dataset data by going to ‘Training data’ and clicking on the upload file button. Your data should be in jsonl format.
Upload your training data by clicking on the TRAINING SET button at the bottom of the page, and if you want to upload a validation set you can do that with the VALIDATION SET button.
Your data has to be in a .jsonl file, where each json object is a conversation with the following structure:
We require a minimum of two valid conversations to begin training. Currently, users are allowed to upload either a single train file, or a train file along with an evaluation file. If an evaluation file is uploaded it must contain at least one conversation.
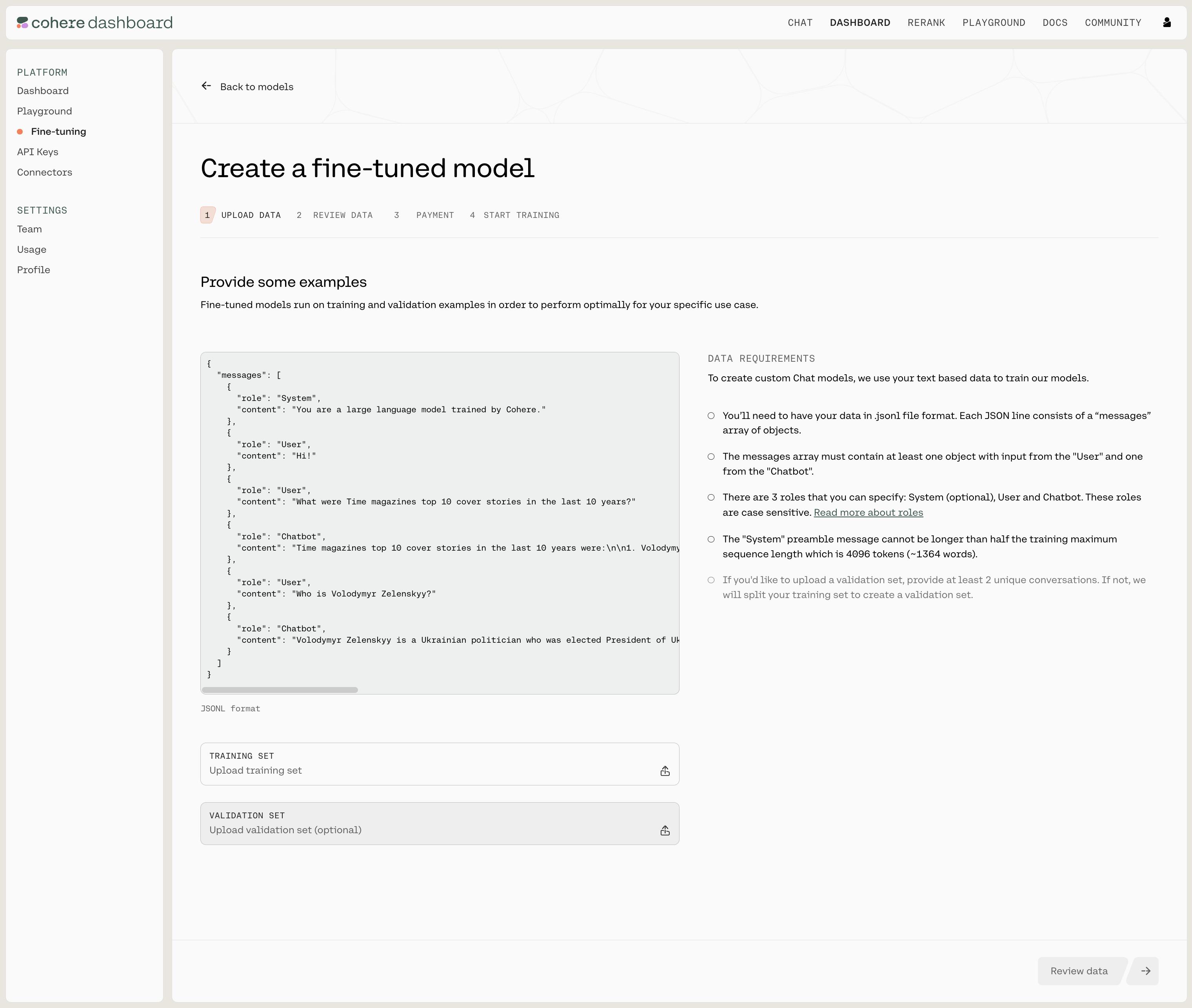
Data Requirements and Errors
There a certain requirements for the data you use to fine-tune a model for Chat through the UI:
- There are only three acceptable values for the
rolefield:System,ChatbotorUser. There should be at least one instance ofChatbotandUserin each conversation. If your dataset includes other roles, a validation error will be thrown. - A system instruction should be uploaded as the first message in the conversation, with
role: System. All other messages withrole: Systemwill be treated as speakers in the conversation. - What’s more, each turn in the conversation should be within the context length of 16384 tokens to avoid being dropped from the dataset. We explain a turn in the ‘Chat Customization Best Practices’ section.
If you need more information, see ‘Preparing the Data’.
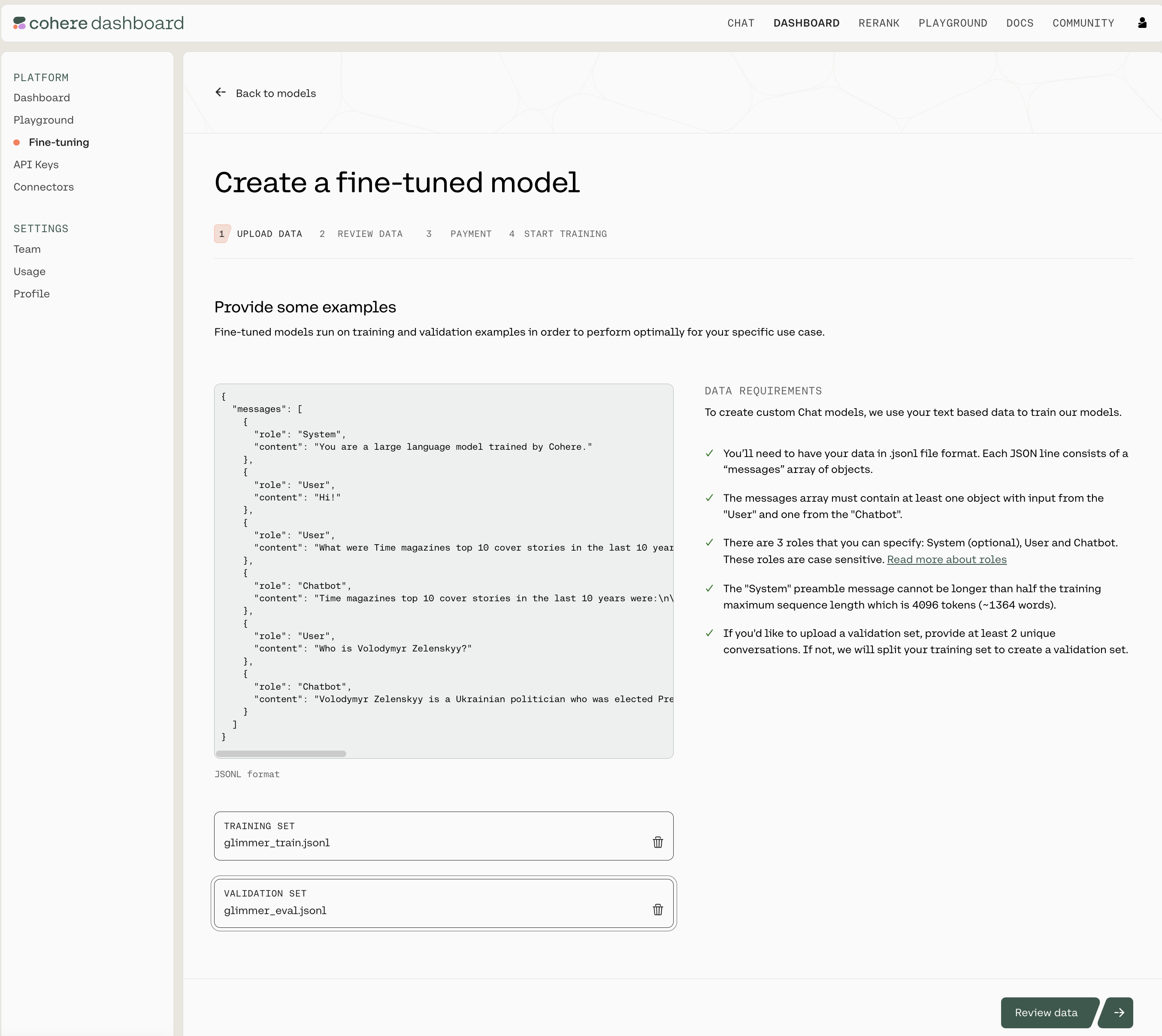
The Cohere platform will automatically check the data you’ve uploaded. If everything is in order, you’ll see a screen like this (note the ‘DATA REQUIREMENTS’ panel on the right):
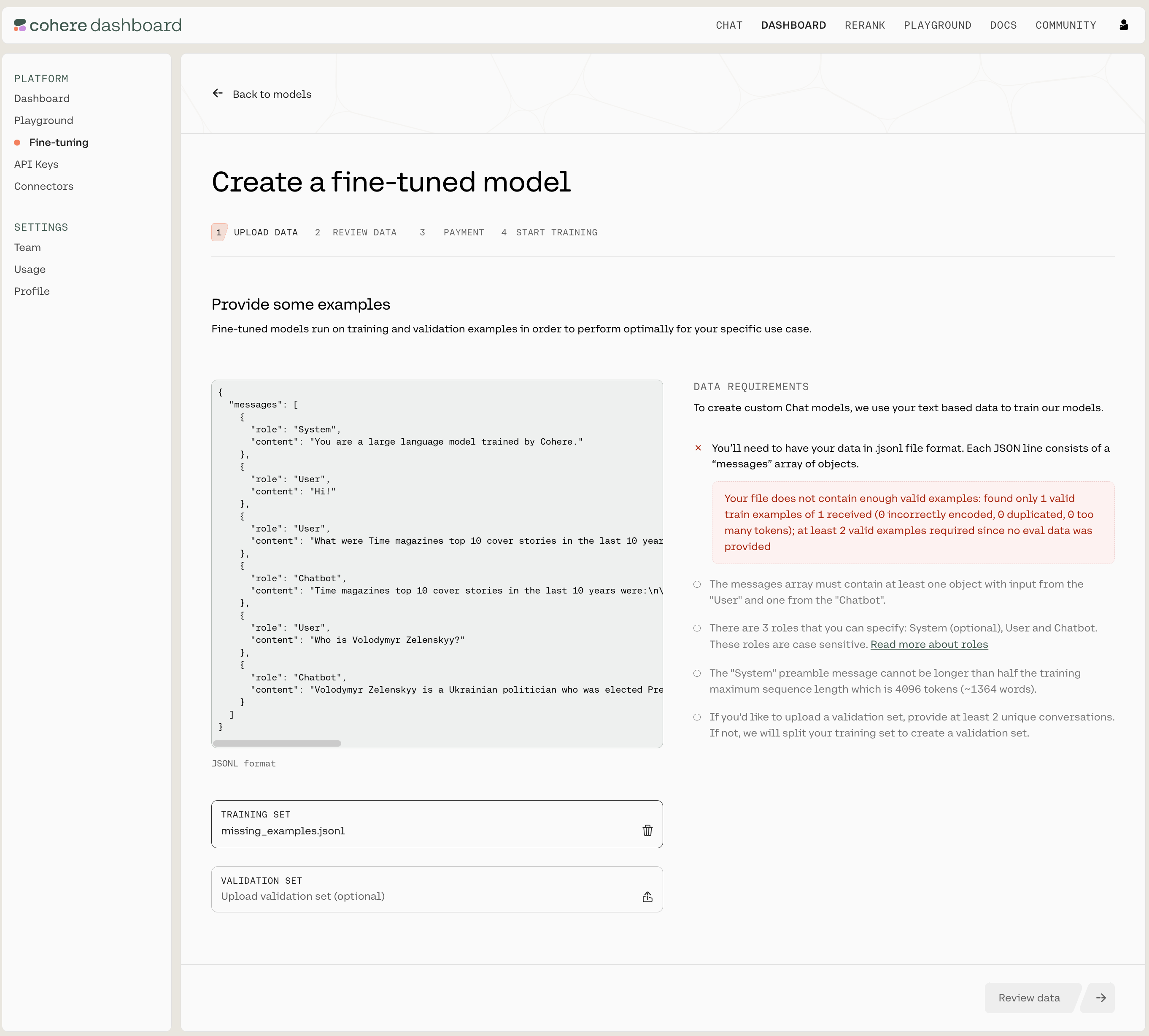
If something is wrong or needs to be amended, you’ll see a screen like this (note the ‘DATA REQUIREMENTS’ panel on the right):
Review Data
The next window will show you the first few samples of your uploaded training and validation datasets.
Here’s what that looks like:
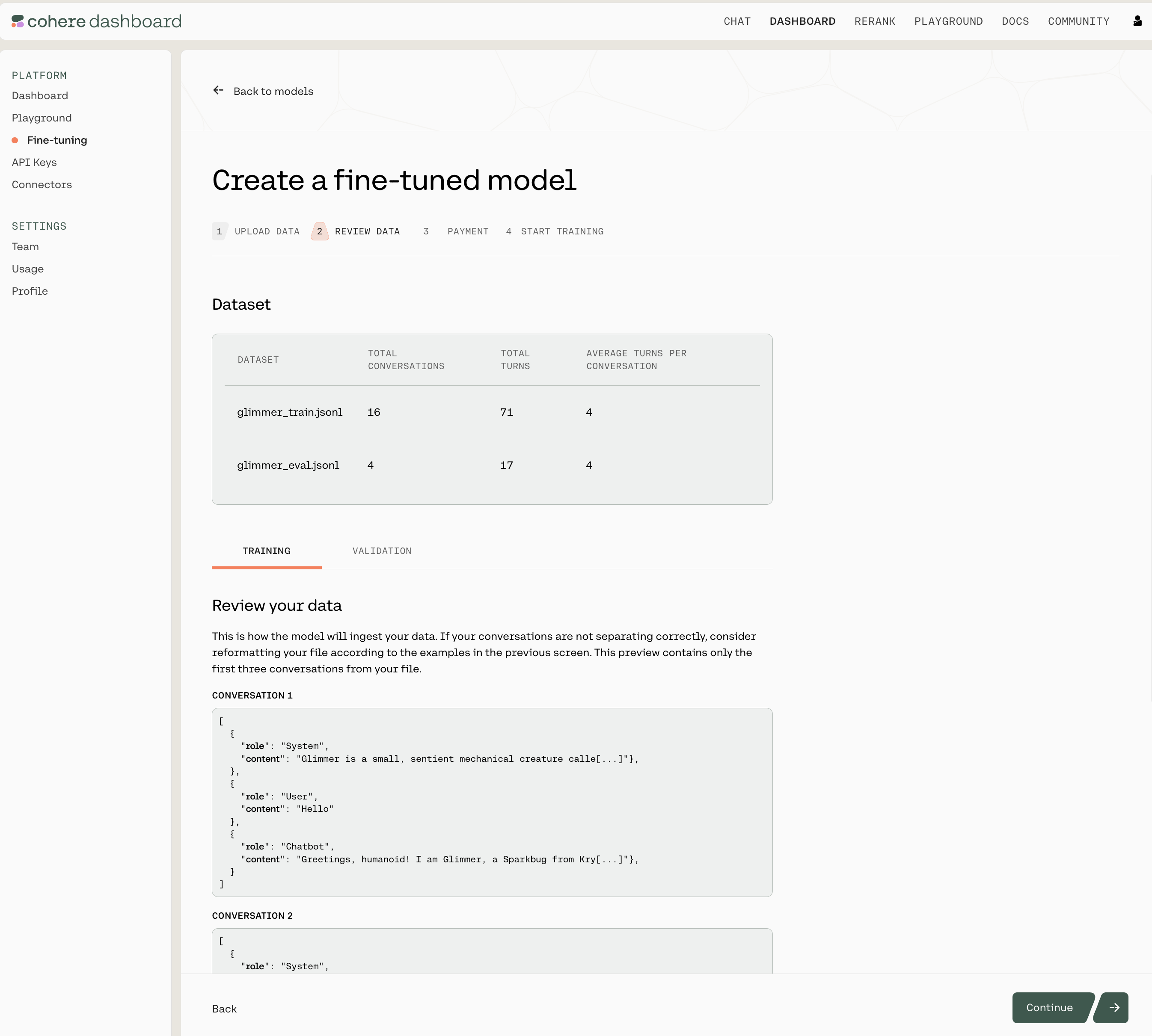
Note that this page shows you the total number of conversations for both the training and validation datasets, the total number of turns in the respective files, and the average turns per conversation. It also includes a sample of the conversations in your data files.
As a reminder, even if you specify a preamble in your dataset, the default inference request to co.chat() will have an empty preamble. If you want to make an inference request with preamble, please pass the parameter preamble.
If you are happy with how the samples look, click on ‘Continue’ at the bottom of the page.
Pricing
This page gives an estimated cost of your fine-tuning job. Please see our latest pricing for more information.

Click next to finalize your fine-tuning job.
Start Training
Now, we’re ready to begin training your fine-tuning model for Chat. Give your model a nickname so you can find it later, and press ‘Start Training’ to kick things off!
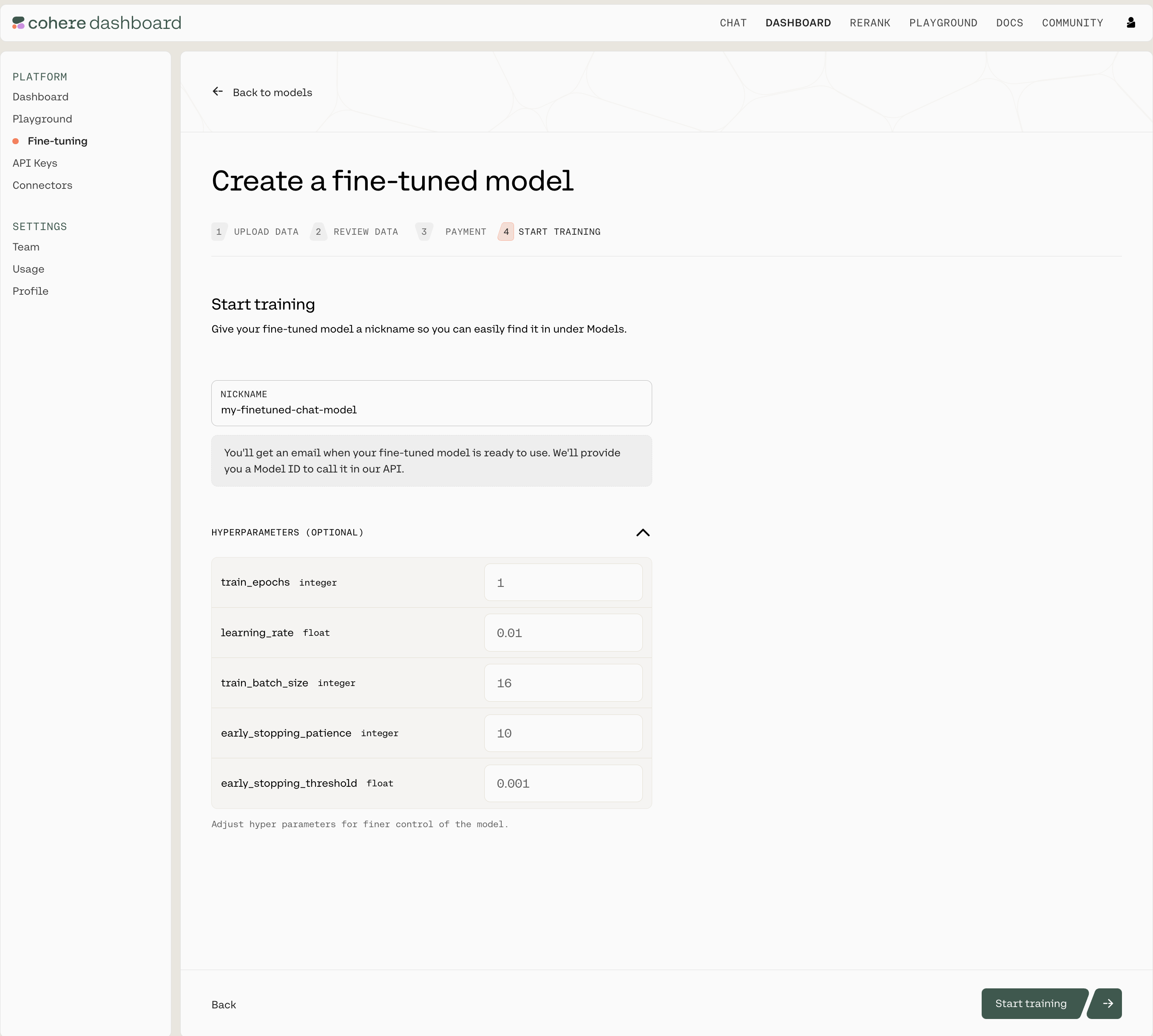
As the training proceeds you’ll receive updates with various accuracy and loss metrics. If you’re not sure what these terms mean, you can go to the ‘Understanding the Chat Fine-tuning Results’ section.
Using the Python SDK
In addition to using the Web UI for fine-tuning models, customers can also kick off fine-tuning jobs programmatically using the Cohere Python SDK. This can be useful for fine-tuning jobs that happen on a regular cadence, such as nightly jobs on newly-acquired data.
Prepare your Dataset
Creating a fine-tuned model that can be used with the co.Chat API requires good examples of data.
Your data has to be in a .jsonl file, where each json object is a conversation with the following structure:
We require a minimum of two valid conversations to begin training. Currently, users are allowed to upload either a single train file, or a train file along with an evaluation file. If an evaluation file is uploaded it must contain at least one conversation.
Create a new Fine-tuned model
Using the co.finetuning.create_finetuned_model() method of the Cohere client, you can kick off a training job that will result in a fine-tuned model. Fine-tuned models are trained on custom datasets which are created using the co.datasets.create() method. In the example below, we create a dataset with training and evaluation data, and use it to fine-tune a model.
Data Formatting and Requirements
Please see the ‘Data Requirements’ section in ‘Preparing the data’ page for the full list of requirements.
After uploading your dataset, via co.datasets.create(), it will be validated. The co.wait(chat_dataset) method will return a cohere.Dataset object with these properties:
validation_statuswill inform you of whether you dataset has beenvalidatedor hasfailed.validation_errorcontains any errors in the case where the validation has failed.validation_warningscontains warnings about your dataset. In the case of your dataset having more than one error, one will appear invalidation_error, and the rest invalidation_warnings.
Below is a table of errors or warnings you may receive and how to fix them.
Parameters
To train a custom model, please see the example below for parameters to pass to co.finetuning.create_finetuned_model(), or visit our API guide. Default hyper parameter values are listed below:
hyperparameters(cohere.finetuning.Hyperparameters) - Adjust hyperparameters for training.train_epochs(int) The maximum number of epochs the customization job runs for. Must be between 1 and 10. Defaults to 1.learning_rate(float) The learning rate to be used during training. Must be between 0.00005 and 0.1. Defaults to 0.01.train_batch_size(int) The batch size is the number of training examples included in a single training pass. Must be between 2 and 16. Defaults to 16.early_stopping_threshold(float) How much the loss must improve to prevent early stopping. Must be between 0.001 and 0.1. Defaults to 0.001.early_stopping_patience(int) Stops training if the loss metric does not improve beyond the value ofearly_stopping_thresholdafter this many rounds of evaluation. Must be between 0 and 10. Defaults to 10.
You can optionally publish the training metrics and hyper parameter values to your Weights and Biases account using the wandb parameter. This is currently only supported when fine-tuning a Chat model.
wandb(cohere.finetuning.WandbConfig) - The Weights & Biases configuration.project(string) The Weights and Biases project to be used during training. This parameter is mandatory.api_key(string) The Weights and Biases API key to be used during training. This parameter is mandatory and will always be stored securely and automatically deleted after the fine-tuning job completes training.entity(string) The Weights and Biases API entity to be used during training. When not specified, it will assume the default entity for that API key.
When the configuration is valid, the Run ID will correspond to the fine-tuned model ID, and Run display name will be the name of the fine-tuned model specified during creation. When specifying a invalid Weights and Biases configuration, the fine-tuned model creation will proceed but nothing will be logged to your Weights and Biases.
Once a fine-tuned model has been created with a specified Weights and Biases configuration, you may view the fine-tuning job run via the Weights and Biases dashboard. It will be available via the following URL: https://wandb.ai/<your-entity>/<your-project>/runs/<finetuned-model-id>.
Example
Calling your Chat Model with the Chat API
Once your model completes training, you can call it via the Chat API and pass your custom model’s ID via the model parameter.
Please note, the model_id is the id returned by the fine-tuned model object with the "-ft" suffix.
co.chat() uses no preamble by default for fine-tuned models. You can specify a preamble using the preamble parameter. Note that for the model parameter, you must pass the finetune’s id with "-ft" appended to the end.
By passing return_prompt=True in any message, you can see which preamble is being used for your conversation.
Here’s a Python script to make this clearer:
After your first message with the model, an id field will be returned which you can pass as the conversation_id to continue the conversation from that point onwards, like so:
We can’t wait to see what you start building! Share your projects or find support on our Discord.