Redis and Cohere (Integration Guide)
Redis and Cohere (Integration Guide)
RedisVL provides a powerful, dedicated Python client library for using Redis as a Vector Database. This walks through how to integrate Cohere embeddings with Redis using a dataset of Wikipedia articles to set up a pipeline for semantic search. It will cover:
- Setting up a Redis index
- Embedding passages and storing them in the database
- Embedding the user’s search query and searching against your Redis index
- Exploring different filtering options for your query
To see the full code sample, refer to this notebook. You can also consult this guide for more information on using Cohere with Redis.
Prerequisites:
The code samples on this page assume the following:
- You have docker running locally
- You have Redis installed (follow this link if you don’t).
- You have a Cohere API Key (you can get your API Key at this link).
Install Packages:
Install and import the required Python Packages:
jsonlines: for this example, the sample passages live in ajsonlfile, and we will use jsonlines to load this data into our environment.redisvl: ensure you are on version0.1.0or latercohere: ensure you are on version4.45or later
To install the packages, use the following code
Import the required packages:
Building a Retrieval Pipeline with Cohere and Redis
Setting up the Schema.yaml:
To configure a Redis index you can either specify a yaml file or import a dictionary. In this tutorial we will be using a yaml file with the following schema. Either use the yaml file found at this link, or create a .yaml file locally with the following configuration.
This index has a name of semantic_search_demo and uses storage_type: hash which means we must set as_buffer=True whenever we call the vectorizer. Hash data structures are serialized as a string and thus we store the embeddings in hashes as a byte string.
For this guide, we will be using the Cohere embed-english-v3.0 model which has a vector dimension size of 1024.
Initializing the Cohere Text Vectorizer:
Create a CohereTextVectorizer by specifying the embedding model and your api key.
The following link contains details around the available embedding models from Cohere and their respective dimensions.
Initializing the Redis Index:
Note that we are using SearchIndex.from_yaml because we are choosing to import the schema from a yaml file, we could also do SearchIndex.from_dict as well.
The above code checks to see if an index has been created. If it has, you should see something like this below:
Look inside the index to make sure it matches the schema you want
You should see something like this:
You can also visit: Localhost Redis GUI. The Redis GUI will show you the index in realtime.
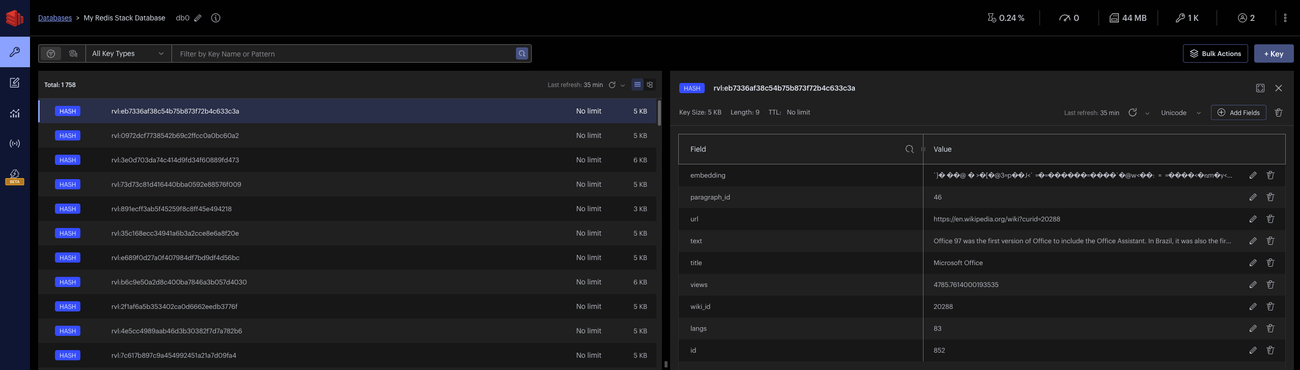
Loading your Documents and Embedding them into Redis:
We will be loading a subset of data which contains paragraphs from wikipedia - the data lives in a jsonl and we will need to parse it to get the text field which is what we are embedding. To do this, we load the file and read it line-by-line, creating a corpus object and a text_to_embed object. We then pass the text_to_embed object into co.embed_many which takes in an list of strings.
Prepare your Data to be inserted into the Index:
We want to preserve all the meta-data for each paragraph into our table and create a list of dictionaries which is inserted into the index
At this point, your Redis DB is ready for semantic search!
Query your Redis DB:
Use the VectorQuery class to construct a query object - here you can specify the fields you’d like Redis to return as well as the number of results (i.e. for this example we set it to 5).
Redis Filters
Adding Tag Filters:
One feature of Redis is the ability to add filtering to your queries on the fly. Here we are constructing a tag filter on the column title which was initialized in our schema with type=tag.
Using Filter Expressions:
Another feature of Redis is the ability to initialize a query with a set of filters called a filter expression. A filter expression allows for the you to combine a set of filters over an arbitrary set of fields at query time.