Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG) is a method for generating text using additional information fetched from an external data source, which can greatly increase the accuracy of the response. When used in conjunction with Command family of models, the Chat API makes it easy to generate text that is grounded on supplementary documents, thus minimizing hallucinations.
A quick example
To call the Chat API with RAG, pass the following parameters as a minimum:
modelfor the model IDmessagesfor the user’s query.documentsfor defining the documents to be used as the context for the response.
The code snippet below, for example, will produce a grounded answer to "Where do the tallest penguins live?", along with inline citations based on the provided documents.
Cohere platform
Private deployment
The resulting generation is"The tallest penguins are emperor penguins, which live in Antarctica.". The model was able to combine partial information from multiple sources and ignore irrelevant documents to arrive at the full answer.
Nice 🐧❄️!
Example response:
The response also includes inline citations that reference the first two documents, since they hold the answers.
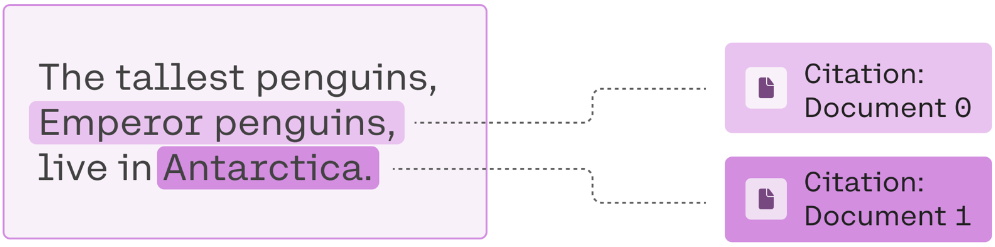
Read more about using and customizing RAG citations here
Three steps of RAG
The RAG workflow generally consists of 3 steps:
- Generating search queries for finding relevant documents. What does the model recommend looking up before answering this question?
- Fetching relevant documents from an external data source using the generated search queries. Performing a search to find some relevant information.
- Generating a response with inline citations using the fetched documents. Generating a response using the fetched documents. This response will contain inline citations, which you can decide to leverage or ignore.
Example: Using RAG to identify the definitive 90s boy band
In this section, we will use the three step RAG workflow to finally settle the score between the notorious boy bands Backstreet Boys and NSYNC. We ask the model to provide an informed answer to the question "Who is more popular: Nsync or Backstreet Boys?"
Step 1: Generating search queries
First, the model needs to generate an optimal set of search queries to use for retrieval.
There are different possible approaches to do this. In this example, we’ll take a tool use approach.
Here, we build a tool that takes a user query and returns a list of relevant document snippets for that query. The tool can generate zero, one or multiple search queries depending on the user query.
Indeed, to generate a factually accurate answer to the question “Who is more popular: Nsync or Backstreet Boys?”, looking up popularity of NSync and popularity of Backstreet Boys first would be helpful.
Customizing the generation of search queries
You can then update the system message and/or the tool definition to generate queries that are more relevant to your use case.
For example, you can update the system message to encourage a longer list of search queries to be generated.
Example response:
Step 2: Fetching relevant documents
The next step is to fetch documents from the relevant data source using the generated search queries. For example, to answer the question about the two pop sensations NSYNC and Backstreet Boys, one might want to use an API from a web search engine, and fetch the contents of the websites listed at the top of the search results.
We won’t go into details of fetching data in this guide, since it’s very specific to the search API you’re querying. However we should mention that breaking up documents into small chunks of ±400 words will help you get the best performance from Cohere models.
Context length limit
When trying to stay within the context length limit, you might need to omit some of the documents from the request. To make sure that only the least relevant documents are omitted, we recommend using the Rerank endpoint endpoint which will sort the documents by relevancy to the query. The lowest ranked documents are the ones you should consider dropping first.
Formatting documents
The Chat endpoint supports a few different options for structuring documents in the documents parameter:
- List of objects with
dataobject: Each document is passed as adataobject (with an optionalidfield to be used in citations). Thedataobject is a string-any dictionary containing the document’s contents. For example, a web search document can contain atitle,text, andurlfor the document’s title, text, and URL. - List of objects with
datastring: Each document is passed as adatastring (with an optionalidfield to be used in citations). - List of strings: Each document is passed as a string.
The following examples demonstrate the options mentioned above.
'data' object
'data' string
string
The id field will be used in citation generation as the reference document IDs. If no id field is passed in an API call, the API will automatically generate the IDs based on the documents position in the list. For more information, see the guide on using custom IDs.
Step 3: Generating a response with citations
In the final step, we will be calling the Chat API again, but this time passing along the documents you acquired in Step 2. We recommend using a few descriptive keys such as "title", "snippet", or "last updated" and only including semantically relevant data. The keys and the values will be formatted into the prompt and passed to the model.
Example response:
In this RAG setting, Cohere models are trained to generate fine-grained citations, out-of-the-box, alongside their text output. Here, we see a sample list of citations, one for each specific span in its response, where it uses the document(s) to answer the question.
For a deeper dive into the citations feature, see the RAG citations guide.
Example response:
Not only will we discover that the Backstreet Boys were the more popular band, but the model can also Tell Me Why, by providing details supported by citations.
For a more in-depth RAG example that leverages the Embed and Rerank endpoints for retrieval, see End-to-end example of RAG with Chat, Embed, and Rerank.
Caveats
It’s worth underscoring that RAG does not guarantee accuracy. It involves giving a model context which informs its replies, but if the provided documents are themselves out-of-date, inaccurate, or biased, whatever the model generates might be as well. What’s more, RAG doesn’t guarantee that a model won’t hallucinate. It greatly reduces the risk, but doesn’t necessarily eliminate it altogether. This is why we put an emphasis on including inline citations, which allow users to verify the information.