Unlocking the Power of Multimodal Embeddings
This Guide Uses the Embed API.
You can find the API reference for the api here
Image capabilities are only compatible with v4.0 and v3.0 models, but v4.0 has features that v3.0 does not have. Consult the embedding documentation for more details.
In this guide, we show you how to use the embed endpoint to embed a series of images. This guide uses a simple dataset of graphs to illustrate how semantic search can be done over images with Cohere. To see an end-to-end example of retrieval, check out this notebook.
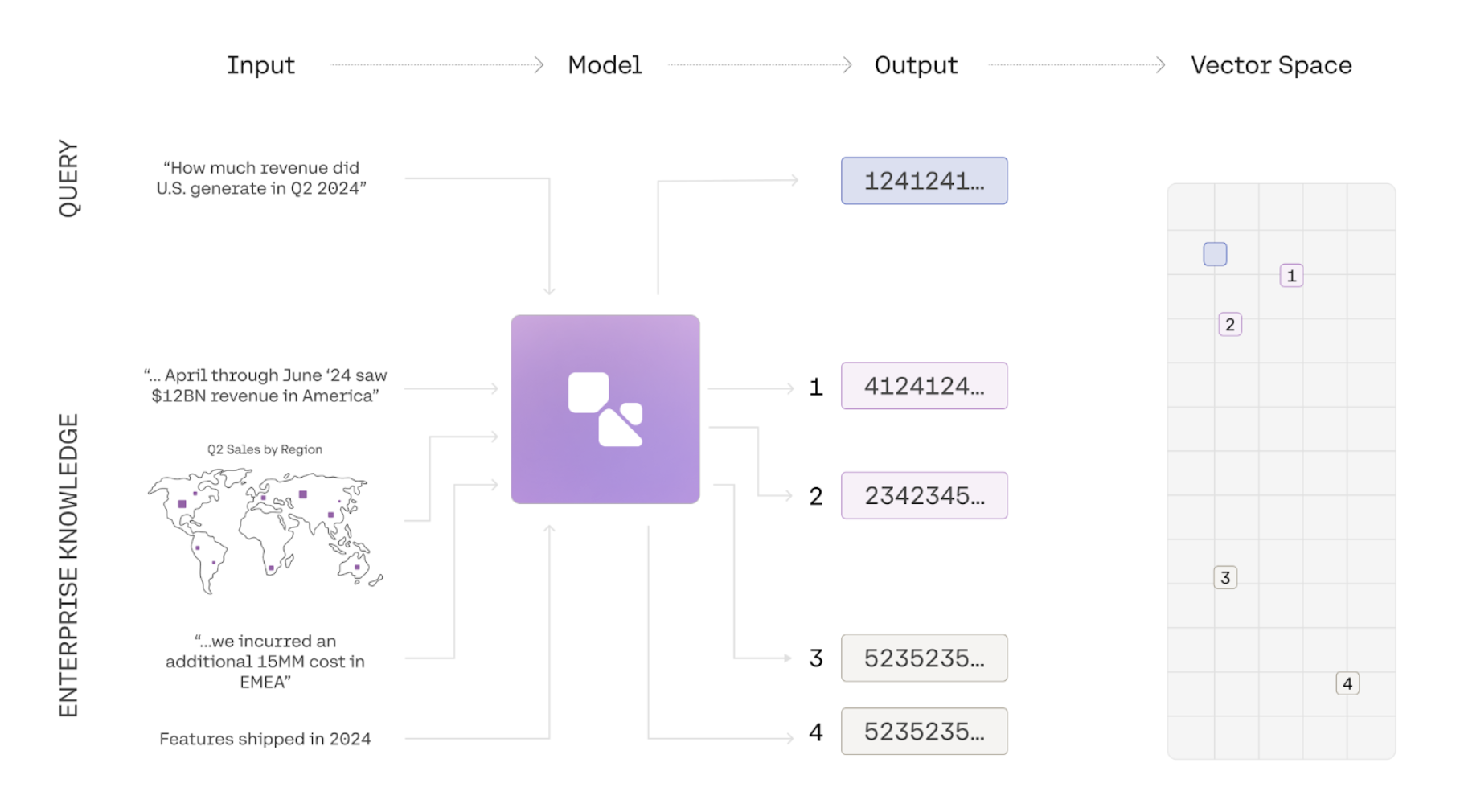
Introduction to Multimodal Embeddings
Information is often represented in multiple modalities. A document, for instance, may contain text, images, and graphs, while a product can be described through images, its title, and a written description. This combination of elements often leads to a comprehensive semantic understanding of the subject matter. Traditional embedding models have been limited to a single modality, and even multimodal embedding models often suffer from degradation in text-to-text or text-to-image retrieval tasks. embed-v4.0 and the embed-v3.0 series of models, however, are fully multimodal, enabling them to embed both images and text effectively. We have achieved state-of-the-art performance without compromising text-to-text retrieval capabilities.
How to use Multimodal Embeddings
1. Prepare your Image for Embeddings
2. Call the Embed Endpoint
Sample Output
Below is a sample of what the output would look like if you passed in a jpeg with original dimensions of 1080x1350 with a standard bit-depth of 24.