The Cohere Datasets API (and How to Use It)
The Cohere Datasets API (and How to Use It)
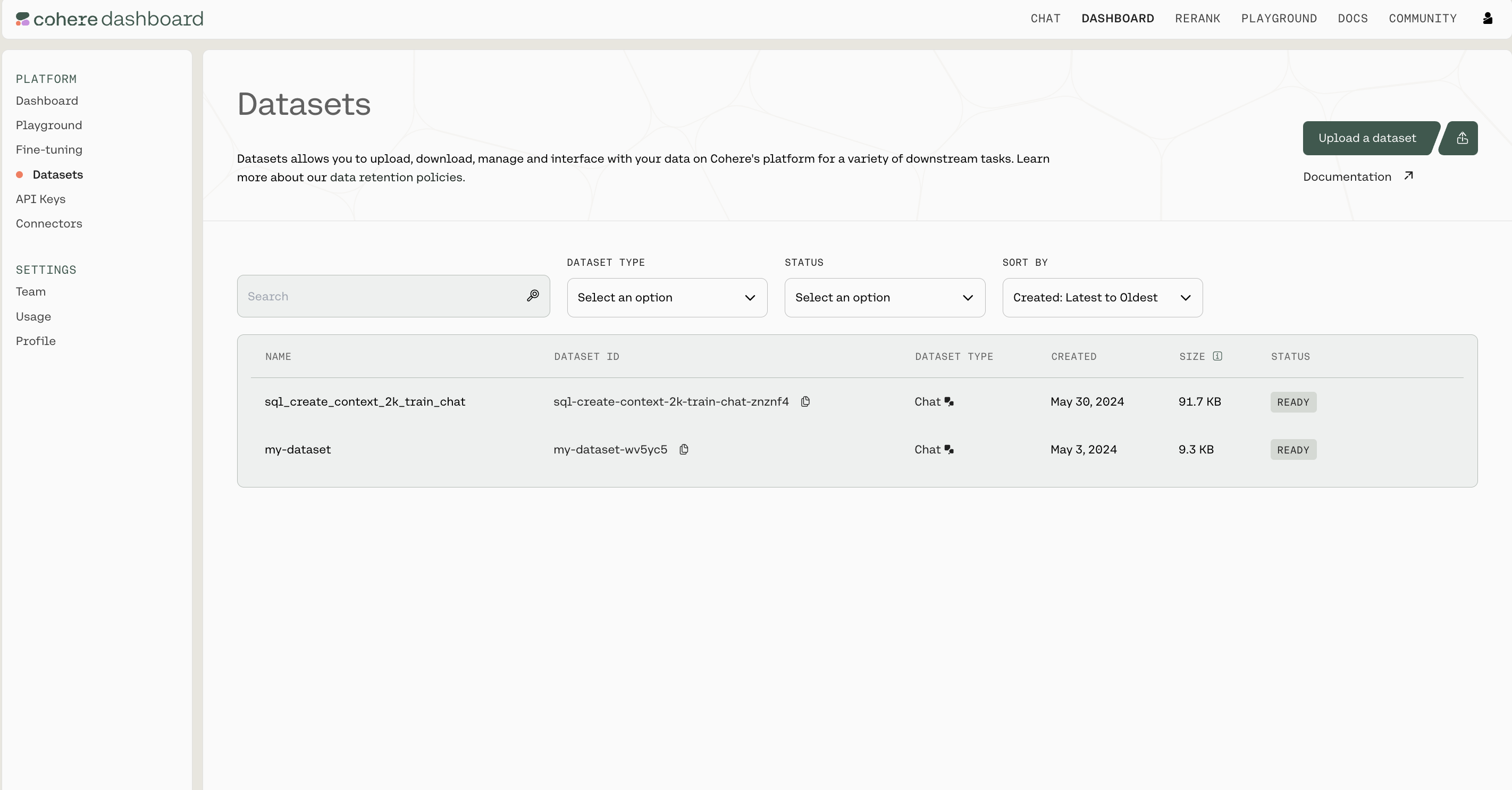
The Cohere platform allows you to upload and manage datasets that can be used in batch embedding with Embedding Jobs. Datasets can be managed in the Dashboard or programmatically using the Datasets API.
File Size Limits
There are certain limits to the files you can upload, specifically:
- A Dataset can be as large as 1.5GB
- Organizations have up to 10GB of storage across all their users
Retention
You should also be aware of how Cohere handles data retention. This is the most important context:
- Datasets get deleted 30 days after creation
- You can also manually delete a dataset in the Dashboard UI or using the Datasets API
Managing Datasets using the Python SDK
Getting Set up
First, let’s install the SDK
Import dependencies and set up the Cohere client.
(All the rest of the examples on this page will be in Python, but you can find more detailed instructions for getting set up by checking out the Github repositories for Python, Typescript, and Go.)
Dataset Creation
Datasets are created by uploading files, specifying both a name for the dataset and the dataset type.
The file extension and file contents have to match the requirements for the selected dataset type. See the table below to learn more about the supported dataset types.
The dataset name is useful when browsing the datasets you’ve uploaded. In addition to its name, each dataset will also be assigned a unique id when it’s created.
Here is an example code snippet illustrating the process of creating a dataset, with both the name and the dataset type specified.
Dataset Validation
Whenever a dataset is created, the data is validated asynchronously against the rules for the specified dataset type . This validation is kicked off automatically on the backend, and must be completed before a dataset can be used with other endpoints.
Here’s a code snippet showing how to check the validation status of a dataset you’ve created.
To help you interpret the results, here’s a table specifying all the possible API error messages and what they mean:
Dataset Metadata Preservation
The Dataset API will preserve metadata if specified at time of upload. During the create dataset step, you can specify either keep_fields or optional_fields which are a list of strings which correspond to the field of the metadata you’d like to preserve. keep_fields is more restrictive, where if the field is missing from an entry, the dataset will fail validation whereas optional_fields will skip empty fields and validation will still pass.
Sample Dataset Input Format
As seen in the above example, the following would be a valid create_dataset call since langs is in the first entry but not in the second entry. The fields wiki_id, url, views and title are present in both JSONs.
Dataset Types
When a dataset is created, the type field must be specified in order to indicate the type of tasks this dataset is meant for.
The following table describes the types of datasets supported by the Dataset API:
Supported Dataset Types
Downloading a dataset
Datasets can be fetched using its unique id. Note that the dataset name and id are different from each other; names can be duplicated, while ids cannot.
Here is an example code snippet showing how to fetch a dataset by its unique id.
Deleting a dataset
Datasets are automatically deleted after 30 days, but they can also be deleted manually. Here’s a code snippet showing how to do that: