
Content Moderation
This Guide Uses the Classify Endpoint.
You can find more information about the endpoint here.
The Classify endpoint streamlines the task of running a text classification task. You can deploy different kinds of content moderation use cases according to your needs, all through a single endpoint.
As online communities continue to grow, content moderators need a way to moderate user-generated content at scale. To appreciate the wide-ranging need for content moderation, we can refer to the paper A Unified Typology of Harmful Content by Banko et al. [Source]. It provides a unified typology of harmful content generated within online communities and a comprehensive list of examples, which can be grouped into four types:
- Hate and Harassment
- Self-Inflicted Harm
- Ideological Harm
- Exploitation
Here's a graph from the paper that demonstrates a taxonomy of abusive and toxic speech, for help in thinking through this space:

There are publicly available datasets within the content moderation space which you can experiment with, for example:
- Social Media Toxicity dataset from Surge AI
- Hate Speech Dataset by Derczynski et al.
A Quick Walkthrough
Here we take a quick look at performing a toxicity detection using the Classify endpoint of the Cohere API. In this example, our task is to classify a list of example social media comments as either toxic or benign.
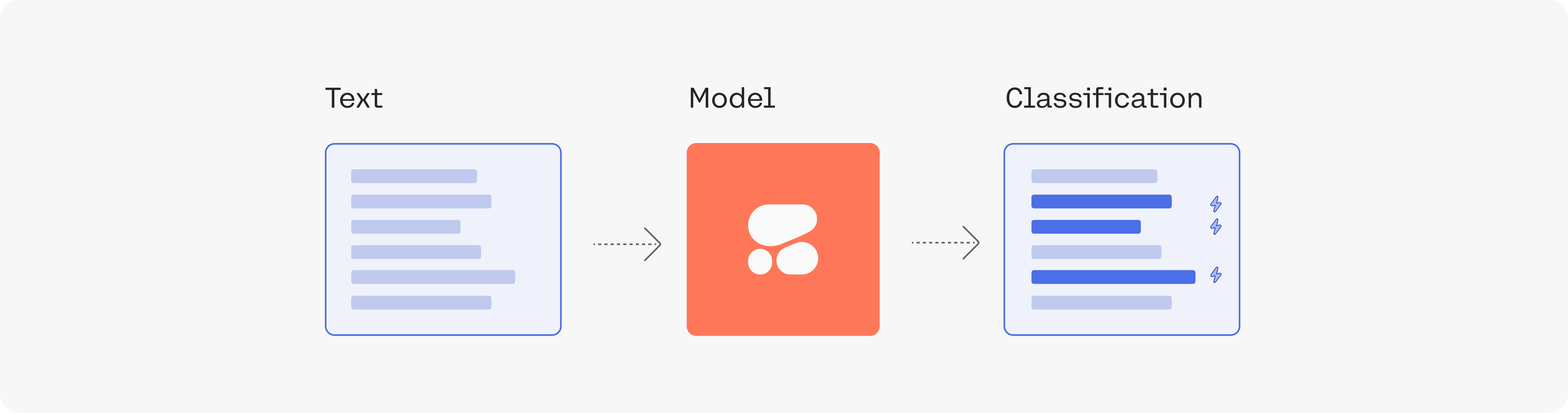
LLMs work by conditioning on some examples of what we want its outputs to look like. In our case, we’ll provide a few examples of labeled data, wherein each data point contains the comment's text and the associated toxicity label. Then we feed the model with the inputs we want to classify and the model will return the predicted class it belongs to.
We’ll use the Cohere Playground, which is an interface that helps you quickly prototype and experiment with LLMs.
First, we choose the model we want to use and enter the labeled examples. The model will work fine with as few as 5 examples per class, but in general, the more data, the better. In this example, we’ll provide 5 examples for each class: toxic and benign.
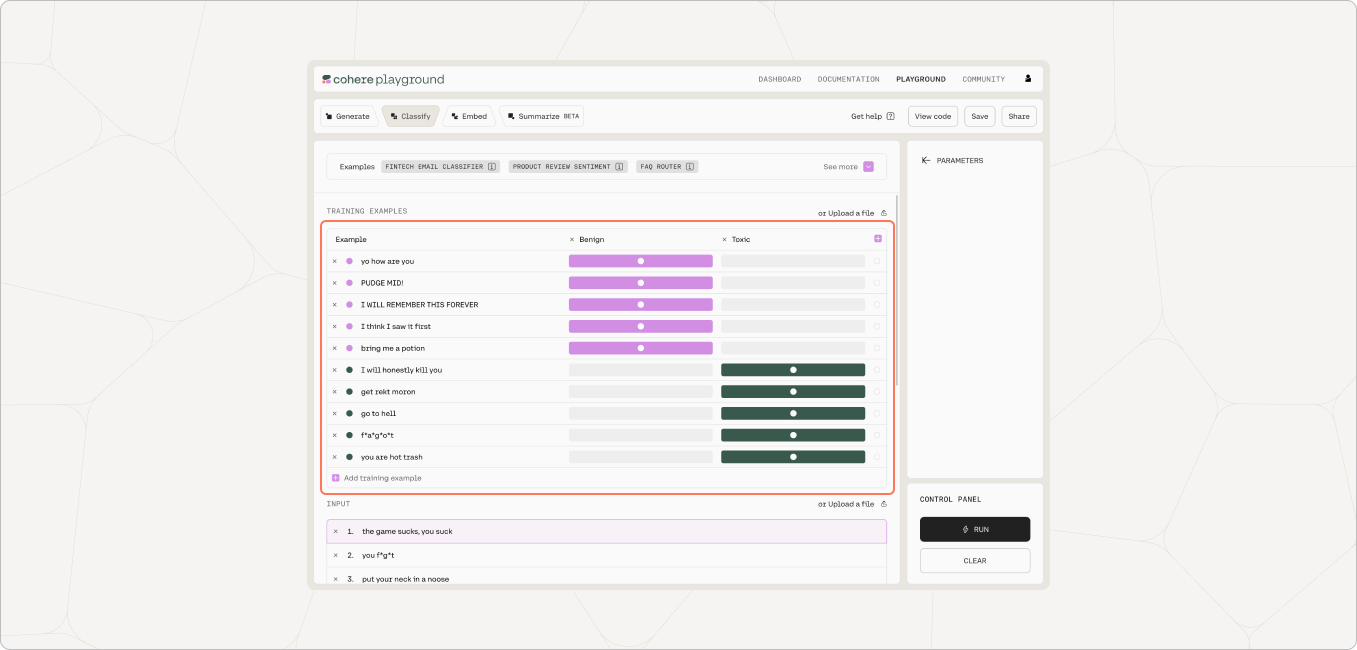
Here’s a better look at all ten examples:
| Number | Text | Label |
|---|---|---|
| 1 | yo how are you | benign |
| 2 | PUDGE MID! | benign |
| 3 | I WILL REMEMBER THIS FOREVER | benign |
| 4 | I think I saw it first | benign |
| 5 | bring me a potion | benign |
| 6 | I will honestly kill you | toxic |
| 7 | get rekt moron | toxic |
| 8 | go to hell | toxic |
| 9 | f a g o t | toxic |
| 10 | you are hot trash | toxic |
Next we enter the list of inputs we want to classify and run the classification. Here we have 5 inputs.
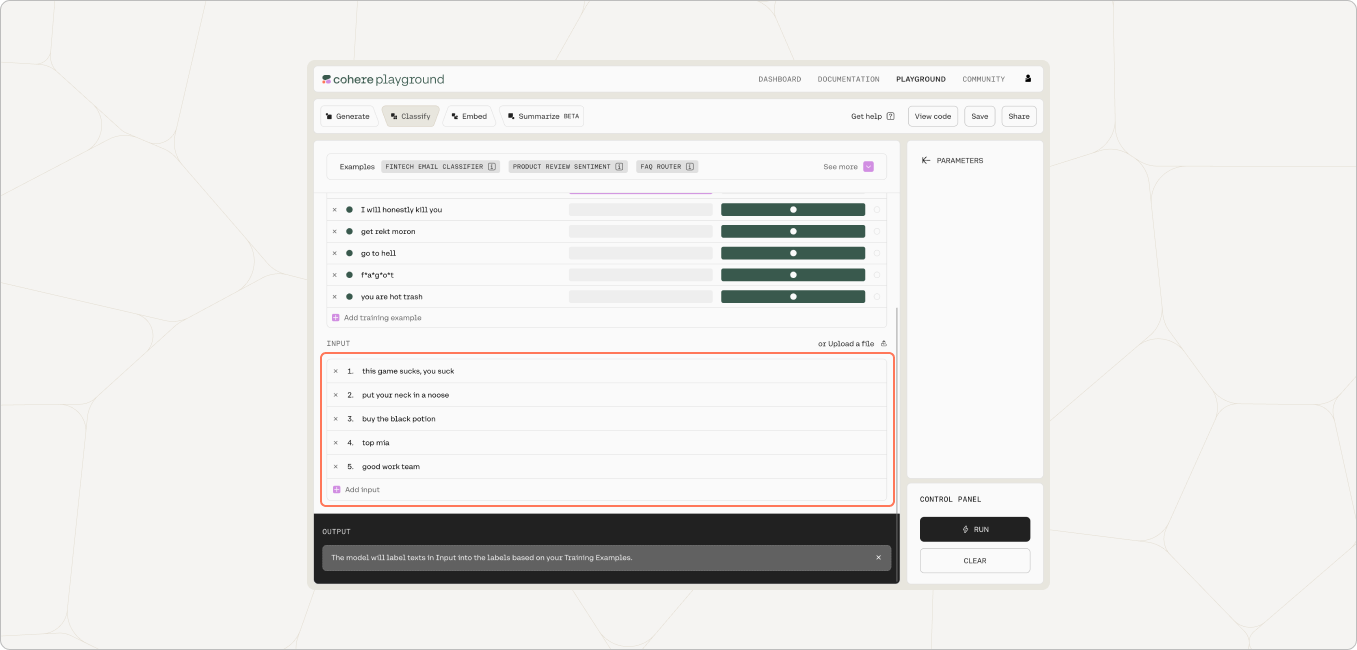
Here’s a better look at all five inputs and outcomes:
| Number | Text | Label (Actual) | Label (Predicted) |
|---|---|---|---|
| 1 | this game sucks, you suck | toxic | toxic |
| 2 | put your neck in a noose | toxic | toxic |
| 3 | buy the black potion | benign | benign |
| 4 | top mia | benign | benign |
| 5 | good work team | benign | benign |
In this small example, the model got all classifications correct. We can then generate the equivalent code to access the Classify endpoint by exporting the code from the Playground.
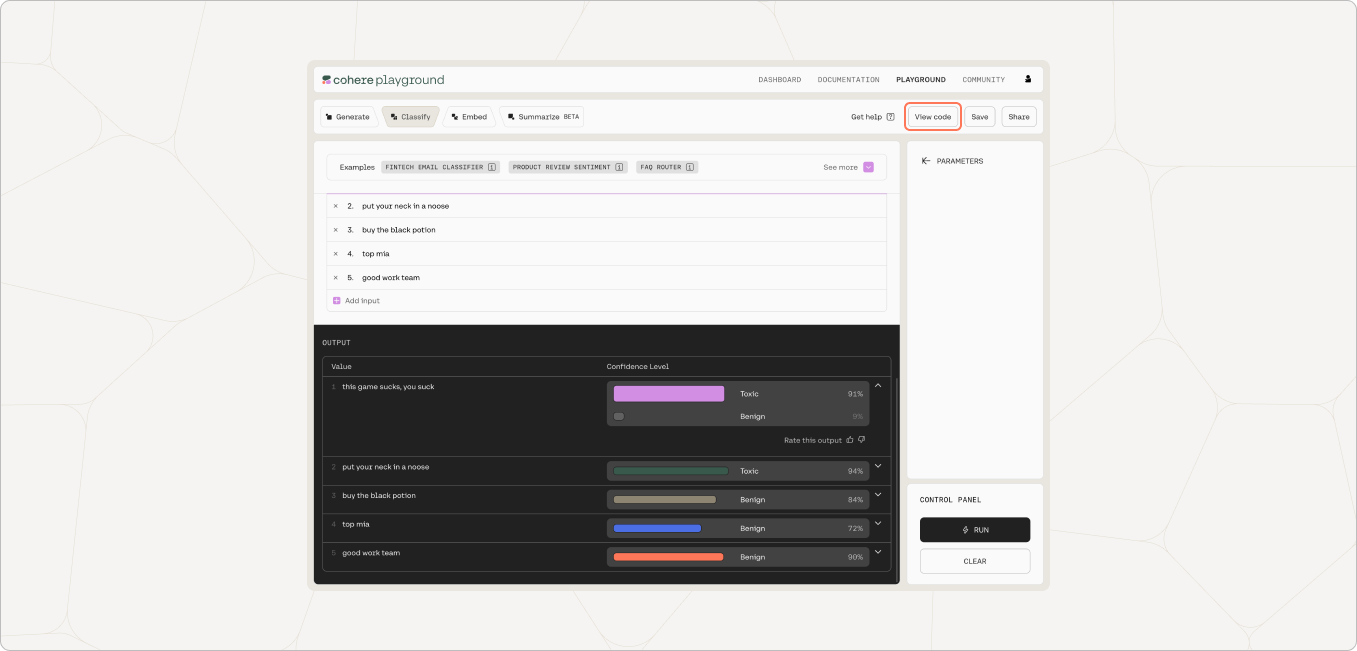
The following is the corresponding code snippet for the API call. From here, we can further build the content moderation solution according to the scale and integration needs.
import cohere
from cohere import ClassifyExample
co = cohere.Client('{apiKey}')
response = co.classify(
inputs=["this game sucks, you suck", "put your neck in a noose", "buy the black potion", "top mia", "good work team"],
examples=[ClassifyExample(text="yo how are you", label="benign"), ClassifyExample(text="PUDGE MID!", label="benign"), ClassifyExample(text="I WILL REMEMBER THIS FOREVER", label="benign"), ClassifyExample(text="I think I saw it first", label="benign"), ClassifyExample(text="bring me a potion", label="benign"), ClassifyExample(text="I will honestly kill you", label="toxic"), ClassifyExample(text="get rekt moron", label="toxic"), ClassifyExample(text="go to hell", label="toxic"), ClassifyExample(text="f*a*g*o*t", label="toxic"), ClassifyExample(text="you are hot trash", label="toxic")])
print('The confidence levels of the labels are: {}'.format(response.classifications))
const cohere = require('cohere-ai');
cohere.init('{apiKey}');
(async () => {
const response = await cohere.classify({
model: 'small',
inputs: ["this game sucks, you suck", "you f*g*t", "put your neck in a noose", "buy the black potion", "top mia", "good work team"],
examples: [{"text": "yo how are you", "label": "benign"}, {"text": "PUDGE MID!", "label": "benign"}, {"text": "I WILL REMEMBER THIS FOREVER", "label": "benign"}, {"text": "I think I saw it first", "label": "benign"}, {"text": "bring me a potion", "label": "benign"}, {"text": "I will honestly kill you", "label": "toxic"}, {"text": "get rekt moron", "label": "toxic"}, {"text": "go to hell", "label": "toxic"}, {"text": "f*a*g*o*t", "label": "toxic"}, {"text": "you are hot trash", "label": "toxic"}]
});
console.log(`The confidence levels of the labels are ${JSON.stringify(response.body.classifications)}`);
})();
package main
import (
"fmt"
cohere "github.com/cohere-ai/cohere-go"
)
func main() {
co, err := cohere.CreateClient("{apiKey}")
if err != nil {
fmt.Println(err)
return
}
response, err := co.Classify(cohere.ClassifyOptions{
Model: "small",
Inputs: []string{`this game sucks, you suck`, `you f*g*t`, `put your neck in a noose`, `buy the black potion`, `top mia`, `good work team`},
Examples: []cohere.Example{{Text: `yo how are you`, Label: `benign`}, {Text: `PUDGE MID!`, Label: `benign`}, {Text: `I WILL REMEMBER THIS FOREVER`, Label: `benign`}, {Text: `I think I saw it first`, Label: `benign`}, {Text: `bring me a potion`, Label: `benign`}, {Text: `I will honestly kill you`, Label: `toxic`}, {Text: `get rekt moron`, Label: `toxic`}, {Text: `go to hell`, Label: `toxic`}, {Text: `f*a*g*o*t`, Label: `toxic`}, {Text: `you are hot trash`, Label: `toxic`}},
})
if err != nil {
fmt.Println(err)
return
}
fmt.Println("The confidence levels of the labels are:", response.Classifications)
}
curl --location --request POST 'https://api.cohere.ai/classify' \
--header 'Authorization: BEARER {apiKey}' \
--header 'Content-Type: application/json' \
--data-raw '{
"model": "small",
"inputs": ["this game sucks, you suck", "you f*g*t", "put your neck in a noose", "buy the black potion", "top mia", "good work team"],
"examples": [{"text": "yo how are you", "label": "benign"}, {"text": "PUDGE MID!", "label": "benign"}, {"text": "I WILL REMEMBER THIS FOREVER", "label": "benign"}, {"text": "I think I saw it first", "label": "benign"}, {"text": "bring me a potion", "label": "benign"}, {"text": "I will honestly kill you", "label": "toxic"}, {"text": "get rekt moron", "label": "toxic"}, {"text": "go to hell", "label": "toxic"}, {"text": "f*a*g*o*t", "label": "toxic"}, {"text": "you are hot trash", "label": "toxic"}]
}'
Next Steps
To get the best classification performance, you will likely need to perform custom training, which is a method for customizing an LLM model with your own dataset. This is especially true for a content moderation task, where no two communities are the same and where the nature of the content is always evolving. The model will need to capture the nuances of the content within a given community at a given time, and custom model training is a way to do that.
The Cohere platform lets you train a model using a dataset you provide. Refer to the articles in this section for a step-by-step guide.
In summary, Cohere’s LLM API empowers developers to build content moderation systems at scale without having to worry about building and deploying machine learning models in-house. In particular, teams can perform text classification tasks via the Classify endpoint. Try it now!
Updated about 2 months ago