
Similarity Between Words and Sentences
Learn when two pieces of text are similar or different.
We’ll use Cohere’s Python SDK for the code examples. Follow along in this notebook.
For large language models, it is crucial to know when two words, or two sentences, are similar or different. This can be a hard problem, but luckily, word and sentence embeddings are very helpful for this task. In this chapter, we go over some different notions of similarity.
Similarity between text
Knowing if two words are similar or different is a very important task for every large language model. An even harder problem is knowing if two different sentences are similar or different. Luckily, word and sentence embeddings are very useful for this task.
In the previous chapter, I explained the concept of word embeddings. In a nutshell, a word embedding is an assignment of a list of numbers (vector) to every word, in a way that semantic properties of the word translate into mathematical properties of the numbers. What do we mean by this? For example, two similar words will have similar vectors, and two different words will have different vectors. But most importantly, each entry in the vector corresponding to a word keeps track of some property of the word. Some of these properties can be understandable to humans, such as age, size, gender, etc., but some others could potentially only be understood by the computer. Either way, we can benefit from these embeddings for many useful tasks.
Sentence embeddings are even more powerful, as they assign a vector of numbers to each sentence, in a way that these numbers also carry important properties of the sentence. One of the Cohere embeddings assigns a vector of length 4096 (i.e., a list of 4096 numbers) to each sentence. Furthermore, multilingual embedding does this for sentences in more than 100 languages. In this way, the sentence “Hello, how are you?” and its corresponding French translation, “Bonjour, comment ça va?” will be assigned very similar numbers, as they have the same semantic meaning.
Now that we know embeddings quite well, let’s move on to using them to find similarities. There are two types of similarities we’ll define in this post: dot product similarity and cosine similarity. Both are very similar and very useful to determine if two words (or sentences) are similar.
Dot Product Similarity
Let’s start with a small example of sentence embedding. For simplicity, let’s consider a dataset of 4 sentences, all movie titles, and an embedding of dimension 2, meaning that each sentence is assigned to two numbers. Let’s say that the embedding is the following:
You’ve Got Mail: [0, 5]
Rush Hour: [6, 5]
Rush Hour 2: [7, 4]
Taken: [7, 0]
Let’s take a closer look at these scores. Would they mean anything? As mentioned before, these scores sometimes mean something that humans can understand, and other times they don’t. In this case, notice that the first score is 0 for You’ve Got Mail, but high for all the other movies. Is there a feature that these three movies have, and that You’ve Got Mail doesn’t? I can think of one: being an action movie. Similarly, the second score is high for You’ve Got Mail, Rush Hour, and Rush Hour 2, but low for Taken. What could this property be? Comedy seems to be one. Therefore, in our embedding, it could well be that the first score is the amount of action in the movie, and the second score is the amount of comedy. The following table represents the embedding.
| Movie | Score 1 (Action) | Score 2 (Comedy) |
|---|---|---|
| You’ve got mail | 0 | 5 |
| Rush Hour | 6 | 5 |
| Rush Hour 2 | 7 | 4 |
| Taken | 7 | 0 |
Now, imagine that we want to find the similarities between these movies. In particular, how similar would you say Taken is from You’ve Got Mail? How similar is Rush Hour to Rush Hour 2? In my opinion, Taken and You’ve Got Mail are very different, and Rush Hour and Rush Hour 2 are very similar. We now need to create a similarity score that is low for the pair [You’ve Got Mail, Taken], and high for the pair [Rush Hour, Rush Hour 2].
Here is one way to create this similarity score. Notice that if two movies are similar, then they must have similar action scores and similar comedy scores. So if we multiply the two action scores, then multiply the two comedy scores, and add them, this number would be high if the scores match. On the other hand, if the scores don’t match very well, the similarity score would be lower. This operation is called the dot product. Let’s see how it works for the two pairs of movies.
- Dot product for the pair [You’ve got mail, Taken] = 0*7 + 5*0 = 0
- Dot product for the pair [Rush Hour, Rush Hour 2] = 6*7 + 5*4 = 62
This matches our intuition since we were expecting a low similarity for the first pair, and a high similarity for the second pair.
Cosine Similarity
Another measure of similarity between sentences (and words) is to look at the angle between them. For example, let’s plot the movie embedding in the plane, where the horizontal axis represents the action score, and the vertical axis represents the comedy score. The embedding looks like this.
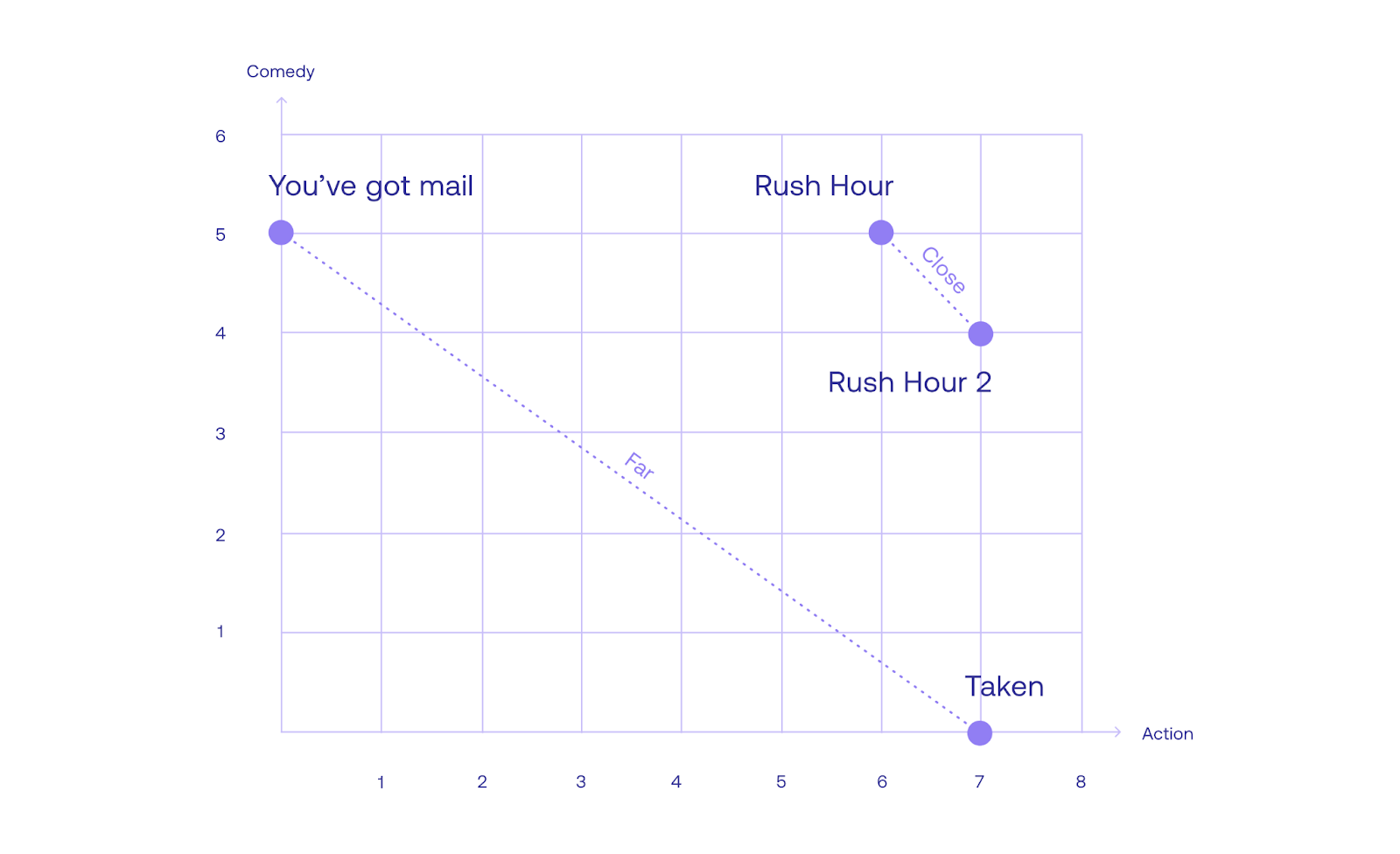
Notice that You’ve Got Mail is quite far from Taken, which makes sense since they are very different movies. Furthermore, Rush Hour and Rush Hour 2 are very close, as they are similar movies. So Euclidean distance (the length of the line between the points) is a good measure for similarity. We need to tweak it a little bit, since we want a measure of similarity that is high for sentences that are close to each other, and low for sentences that are far away from each other. Distance does the exact opposite. So in order to tweak this metric, let’s look at the angle between the rays from the origin (the point with coordinates [0,0]), and each sentence. Notice that this angle is small if the points are close to each other, and large if the points are far away from each other. Now we need the help of another function, the cosine. The cosine of angles close to zero is close to 1, and as the angle grows, the cosine decreases. This is exactly what we need. Therefore, we define the cosine distance as the cosine of the angle formed by the two rays going from the origin, to the two sentences.
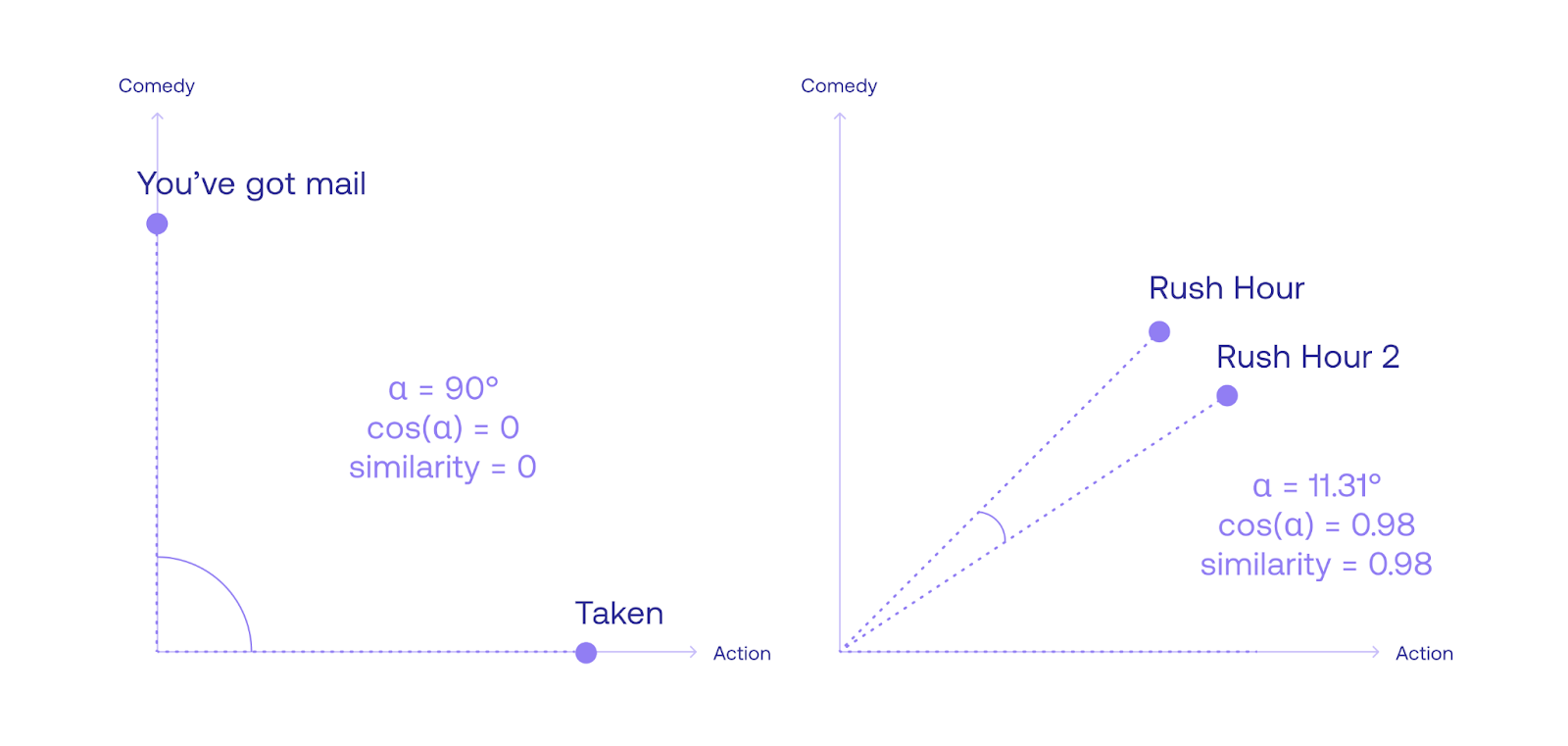
Notice that in the ongoing example, the angle between the movies You’ve Got Mail, and Taken, is 90 degrees, with a cosine of 0. Therefore, the similarity between them is 0. On the other hand, the angle between the movies Rush Hour and Rush Hour 2 is 11.31 degrees. Its cosine is 0.98, which is quite high. In fact, the similarity between a sentence and itself is always 1, as the angle is 0, with a cosine of 1.
Real-Life Example
Of course, this was a very small example. Let’s do a real-life example with the Cohere embedding.
To set up, we first import several tools we'll need.
import numpy as np
import seaborn as sns
import altair as alt
from sklearn.metrics.pairwise import cosine_similarity
We also import the Cohere module and create a client.
import cohere
co = cohere.Client("COHERE_API_KEY") # Your Cohere API key
Consider the following 3 sentences, stored in the Python list texts.
texts = ["I like to be in my house",
"I enjoy staying home",
"the isotope 238u decays to 206pb"]
One would expect the two first sentences to have a high similarity score when compared to each other, and the third one to have a very low similarity score when compared to the other two.
To get the corresponding sentence embeddings, we call the Embed endpoint with co.embed(). We supply three parameters:
texts- our list of sentencesmodel- we useembed-english-v3.0, Cohere's latest (at the time of writing) English-only embeddings model to generate the embeddingsinput_type- we usesearch_documentto indicate that we intend to use the embeddings for search use-cases
You'll learn about these parameters in more detail in the LLMU Module on Text Representation.
response = co.embed(
texts=texts,
model='embed-english-v3.0',
input_type='search_document'
)
The embeddings are stored in the embeddings value of the response. After getting the embeddings, we separate them by sentence and print the values.
embeddings = response.embeddings
[sentence1, sentence2, sentence3] = embeddings
print("Embedding for sentence 1", np.array(sentence1))
print("Embedding for sentence 2", np.array(sentence2))
print("Embedding for sentence 3", np.array(sentence3))
The results are as follows:
Embedding for sentence 1 [ 0.04968262 0.03799438 -0.02963257 ... -0.0737915 -0.0079422
-0.01863098]
Embedding for sentence 2 [ 0.043396 0.05401611 -0.02461243 ... -0.06216431 -0.0196228
-0.00948334]
Embedding for sentence 3 [ 0.0243988 0.00712967 -0.04669189 ... -0.03903198 -0.02403259
0.01942444]
Note that the embeddings are vectors (lists) of 1024 numbers, so they are truncated here (thus the dots in between). One would expect that the vectors corresponding to sentences 1 and 2 are similar to each other and that both are different from the vector corresponding to sentence 3. However, from inspection, this is not very clear. We need to calculate some similarities to see if this is the case.
Dot Product Similarity
Let’s calculate the dot products between the three sentences. The following line of code will do it.
print("Similarity between sentences 1 and 2:", np.dot(sentence1, sentence2))
print("Similarity between sentences 1 and 3:", np.dot(sentence1, sentence3))
print("Similarity between sentences 2 and 3:", np.dot(sentence2, sentence3))
And the results are:
Similarity between sentences 1 and 2: 0.818827121924668
Similarity between sentences 1 and 3: 0.19770800712384107
Similarity between sentences 2 and 3: 0.19897217756830138
The similarity between sentences 1 and 2 (0.8188) is much larger than the similarities between the other pairs. This confirms our predictions.
Just for consistency, we also calculate the similarities between each sentence and itself, to confirm that a sentence and itself has the highest similarity score.
Similarity between sentences 1 and 1: 0.9994656785851899
Similarity between sentences 2 and 2: 1.0006820582016114
Similarity between sentences 3 and 3: 1.0005095878377965
This checks out—the similarity between a sentence and itself is around 1, which is higher than all the other similarities.
Cosine Similarity
Now let’s calculate the cosine similarities between them.
print("Cosine similarity between sentences 1 and 2:", cosine_similarity([sentence1], [sentence2])[0][0])
print("Cosine similarity between sentences 1 and 3:", cosine_similarity([sentence1], [sentence3])[0][0])
print("Cosine similarity between sentences 2 and 3:", cosine_similarity([sentence2], [sentence3])[0][0])
The results are the following:
Cosine similarity between sentences 1 and 2: 0.818766792354783
Cosine similarity between sentences 1 and 3: 0.1977104790996451
Cosine similarity between sentences 2 and 3: 0.19885369669720415
Next, we check the cosine similarity between each sentence and itself.
Cosine similarity between sentences 1 and 1: 0.9999999999999998
Cosine similarity between sentences 2 and 2: 1.0000000000000004
Cosine similarity between sentences 3 and 3: 1.0000000000000004
We also plot the results in a grid.
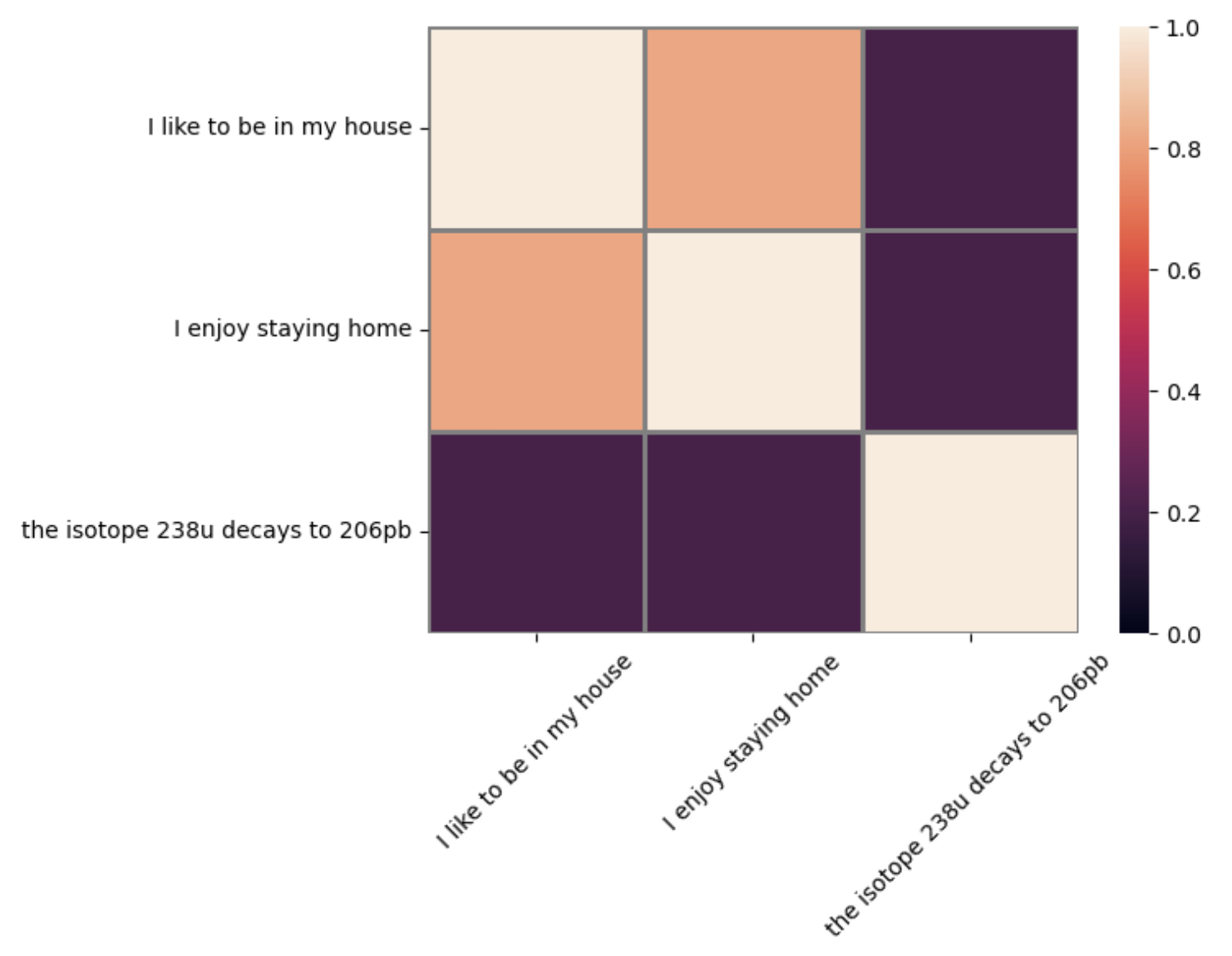
The similarity between each sentence and itself is 1 (the diagonal in the plot), which is consistent with our expectations. Furthermore, a sentence and itself represent the same point in space, which gives an angle of 0 with the origin, so it makes sense that the similarity is the cosine of 0, which is 1!
Notice that the dot product and cosine distance give nearly identical values. The reason for this is that the embedding is normalized (meaning each vector has norm equal to 1). When the embedding is not normalized, the dot product and cosine distance would give different values.
Conclusion
In the previous chapter, we learned that sentence embeddings are the bread and butter of language models, as they associate each sentence with a particular list of numbers (a vector), in a way that similar sentences give similar vectors. We can think of embeddings as a way to locate each sentence in space (a high dimensional space, but a space nonetheless), in a way that similar sentences are located close by. Once we have each sentence somewhere in space, it’s natural to think of distances between them. And an even more intuitive way to think of distances is to think of similarities, i.e., a score assigned to each pair of sentences, which is high when these sentences are similar, and low when they are different. The similarity is a very useful concept in large language models, as it can be used for search, for translation, for summarization, and in many other applications. To learn more about these applications, stay tuned for the next article!
Original Source
This material comes from the post What is Similarity Between Sentences?
Updated 18 days ago
The attention mechanism adds context to the LLM. Learn about it here!