Semantic Search
This Guide Uses the Embed Endpoint.
You can find more information about the endpoint here.
Language models give computers the ability to search by meaning and go beyond searching by matching keywords. This capability is called semantic search.
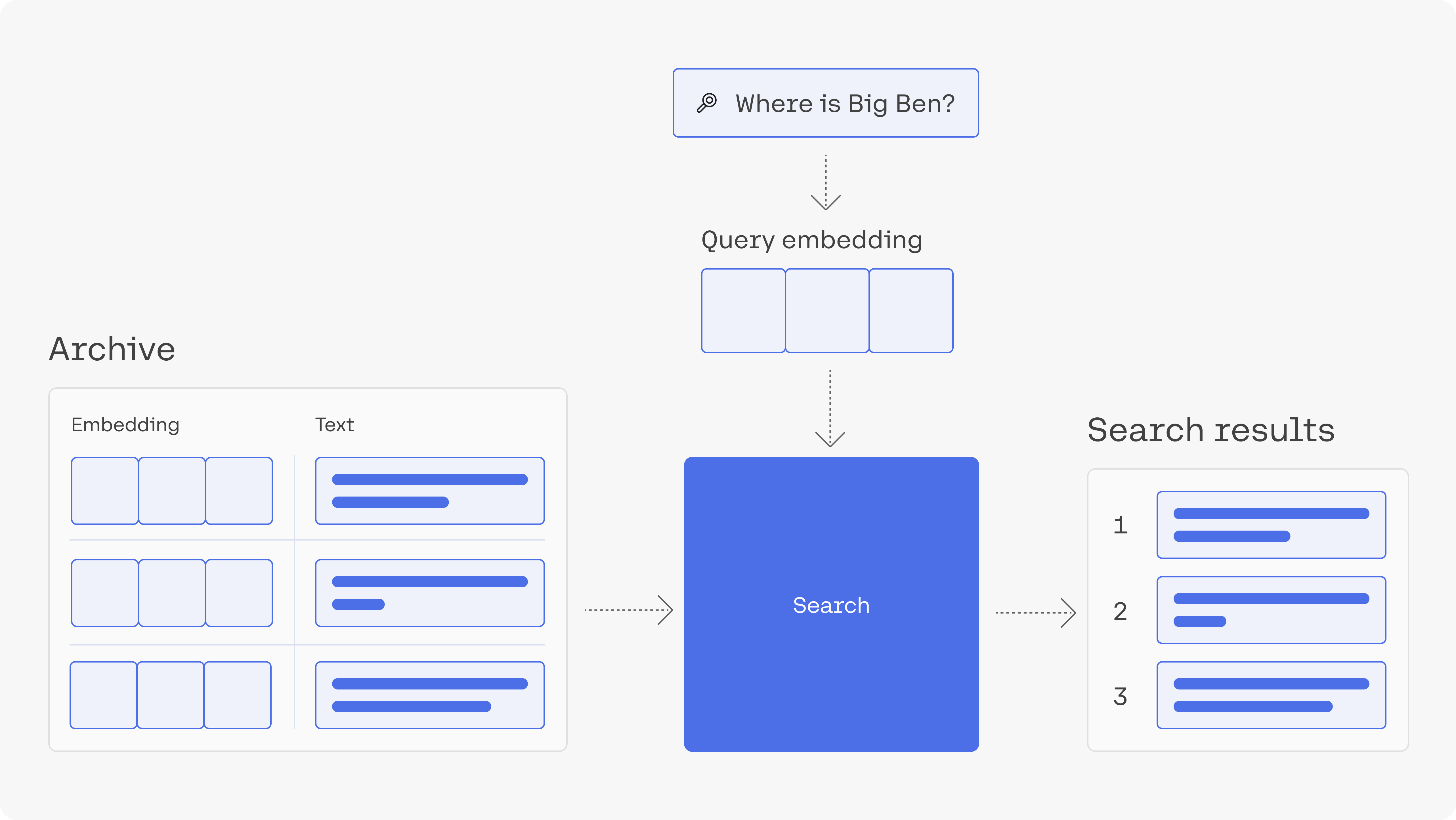 In this article, we’ll build a simple semantic search engine. The applications of semantic search go beyond building a web search engine. They can empower a private search engine for internal documents or records. It can be used to power features like StackOverflow’s “similar questions” feature.
In this article, we’ll build a simple semantic search engine. The applications of semantic search go beyond building a web search engine. They can empower a private search engine for internal documents or records. It can be used to power features like StackOverflow’s “similar questions” feature.
You can find the code in the notebook and colab.
Contents
- Getting set up
- Get the archive of questions
- Embed the archive
- Search using an index and nearest neighbour search
- Visualize the archive based on the embeddings.
New to Cohere?
Get Started now and get unprecedented access to world-class Generation and
Representation models with billions of parameters.
1. Download the Dependencies
And if you’re running an older version of the SDK, you might need to upgrade it like so:
If you’re running this in a jupyter notebook, you’ll need to prepend a ! to the pip install statement:
Get your Cohere API key by signing up here. Paste it in api_key below.
1a. Import the Necessary Dependencies to Run this Example
2. Get the Archive of Questions
We’ll use the trec dataset which is made up of questions and their categories.
3. Embed the Archive
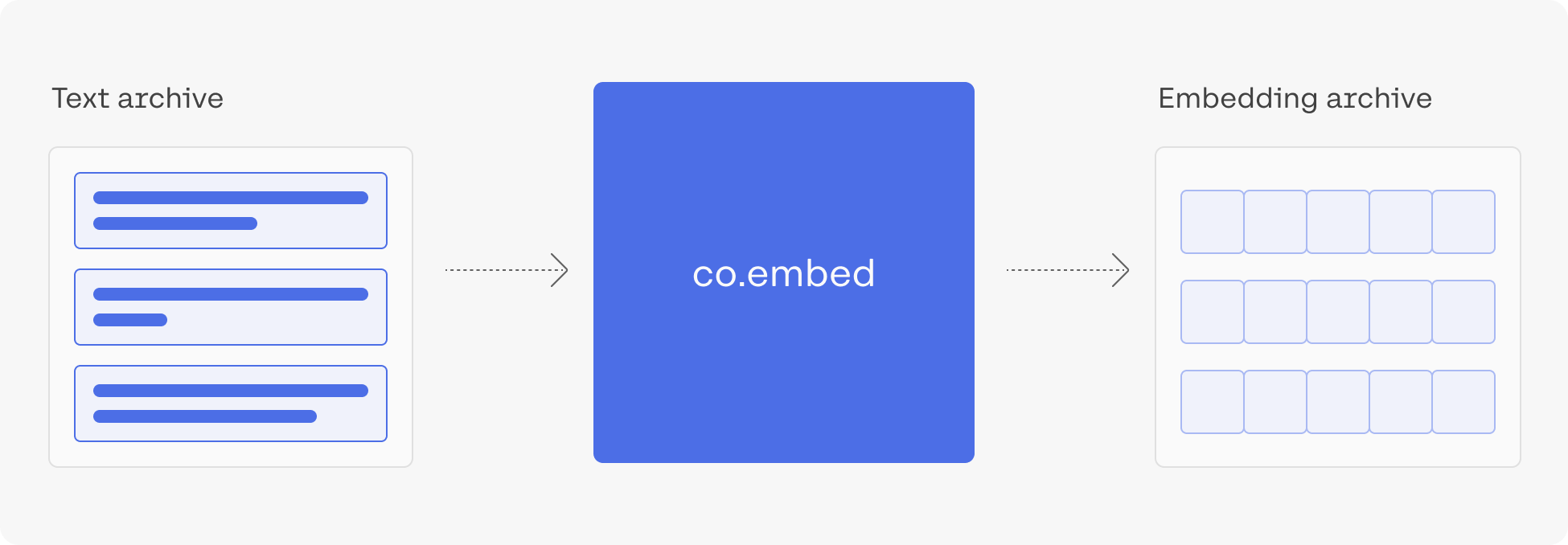
Let’s now embed the text of the questions.
To get a thousand embeddings of this length should take a few seconds.
4. Build the Index, search Using an Index and Conduct Nearest Neighbour Search
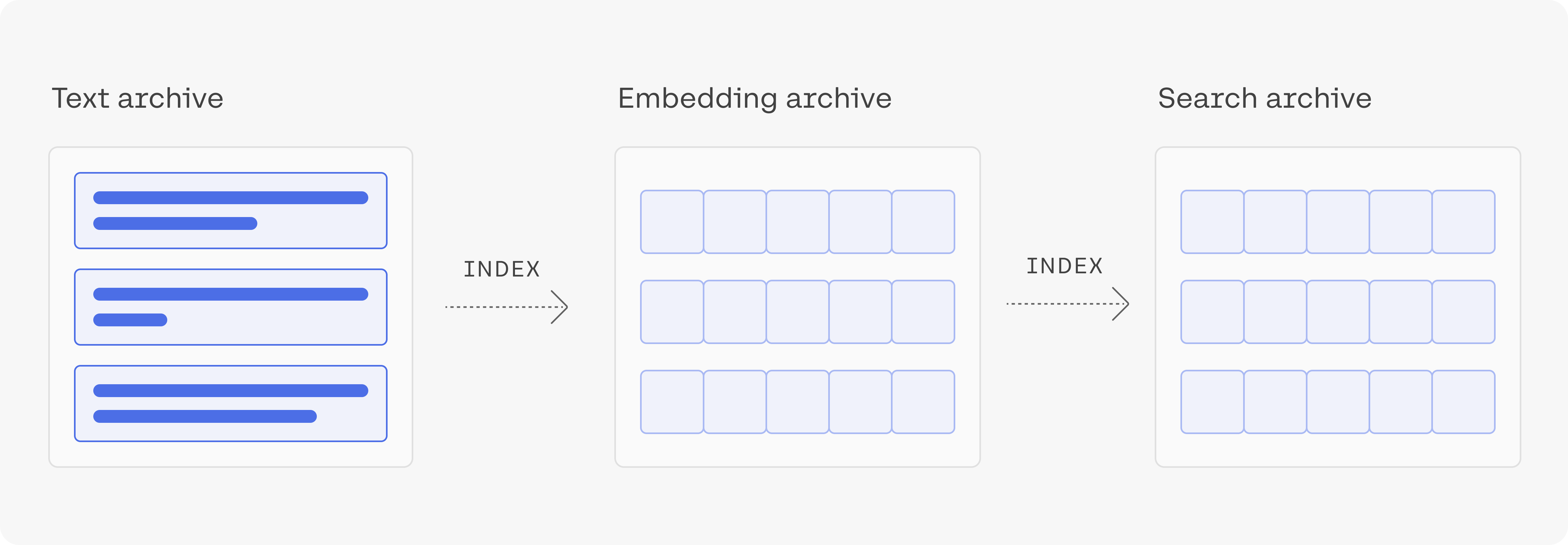
Let’s build an index using the library called annoy. Annoy is a library created by Spotify to do nearest neighbour search. Nearest neighbour search is an optimization problem that involves finding the point in a given set that is closest (or most similar) to a given point.
After building the index, we can use it to retrieve the nearest neighbours either of existing questions (section 3.1), or of new questions that we embed (section 3.2).
4a. Find the Neighbours of an Example from the Dataset
If we’re only interested in measuring the similarities between the questions in the dataset (no outside queries), a simple way is to calculate the similarities between every pair of embeddings we have.
4b. Find the Neighbours of a User Query
We’re not limited to searching using existing items. If we get a query, we can embed it and find its nearest neighbours from the dataset.
5. Visualize the Archive
Use the code below to create a visualization of the embedded archive. As written, this code will only run in a jupyter notebook.
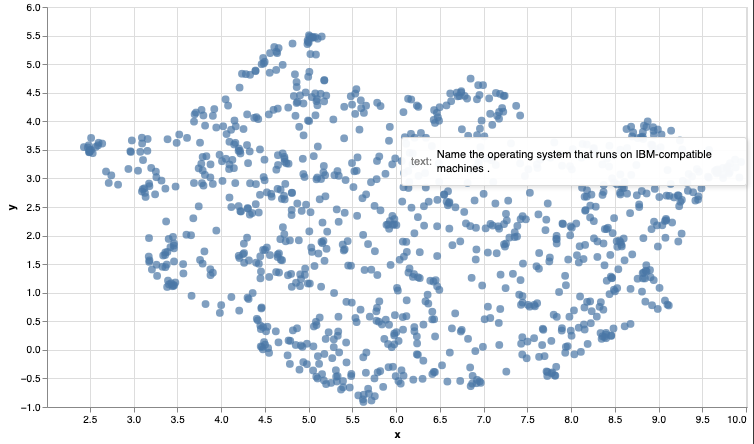
This concludes this introductory guide to semantic search using sentence embeddings. As you continue the path of building a search product additional considerations arise, such as dealing with long texts, or training to better improve the embeddings for a specific use case.
We can’t wait to see what you start building! Share your projects or find support on our community discord.