Top-k & Top-p
Top-k & Top-p
The method you use to pick output tokens is an important part of successfully generating text with language models. There are several methods (also called decoding strategies) for picking the output token, with two of the leading ones being top-k sampling and top-p sampling.
Let’s look at the example where the input to the model is the prompt The name of that country is the:
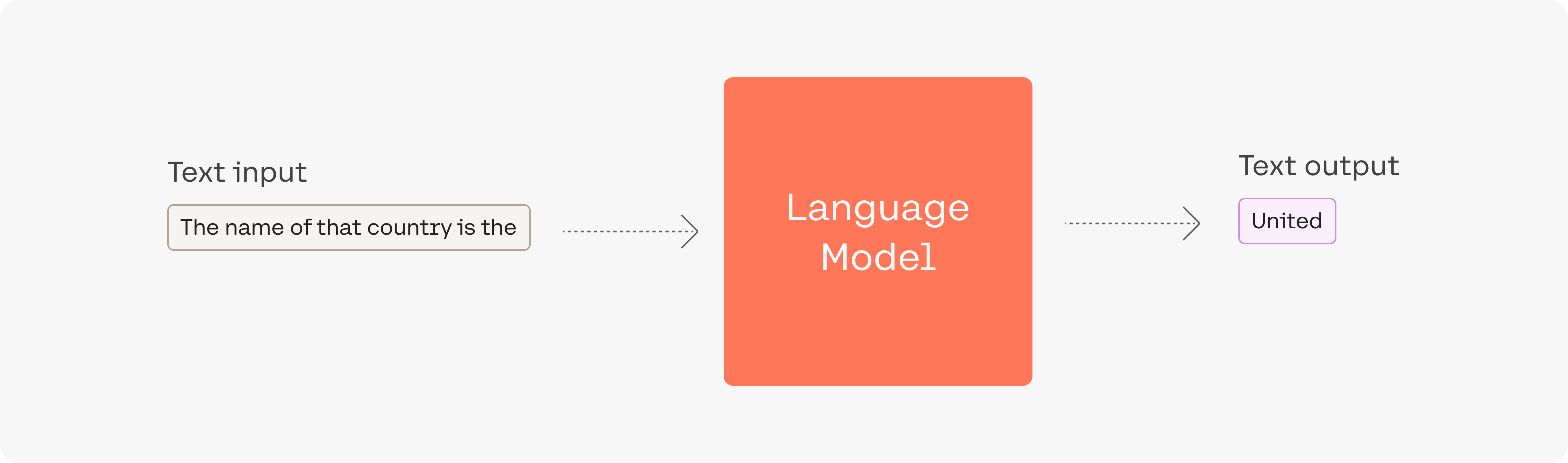
The output token in this case, Unitedwas picked in the last step of processing — after the language model has processed the input and calculated a likelihood score for every token in its vocabulary. This score indicates the likelihood that it will be the next token in the sentence (based on all the text the model was trained on).
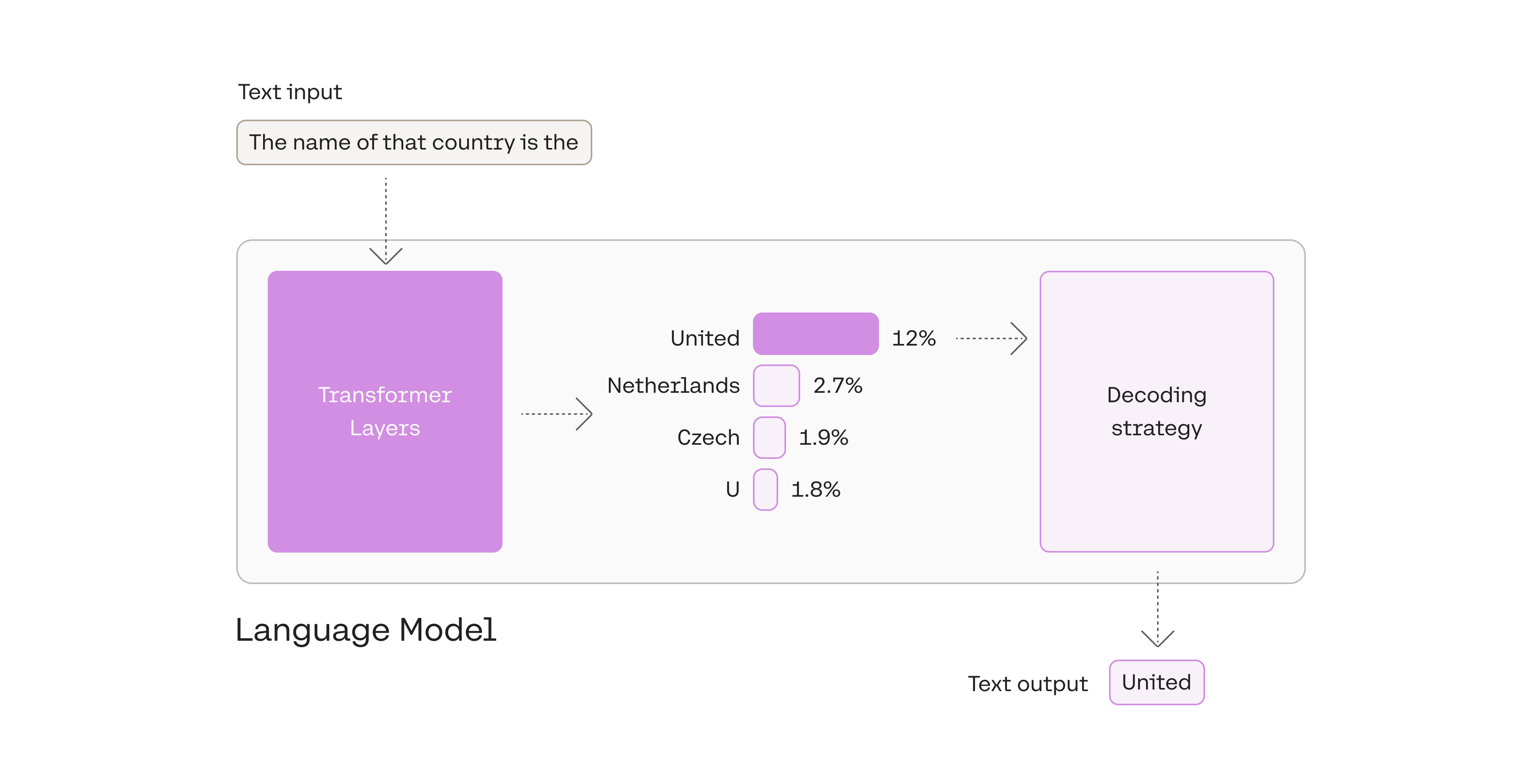
1. Pick the top token: greedy decoding
You can see in this example that we picked the token with the highest likelihood, United.
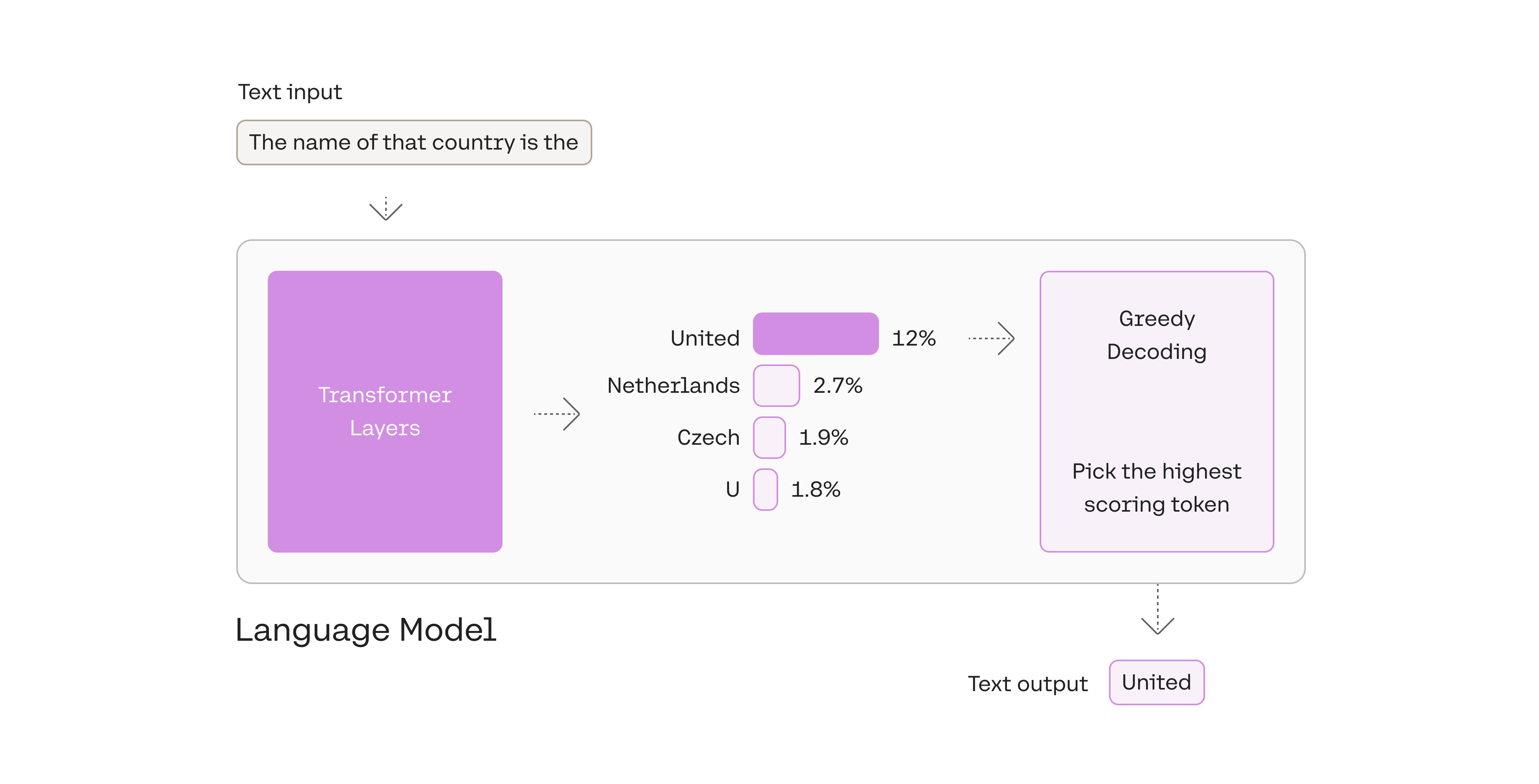
Greedy decoding is a reasonable strategy, but has some drawbacks; outputs can get stuck in repetitive loops, for example. Think of the suggestions in your smartphone’s auto-suggest. When you continually pick the highest suggested word, it may devolve into repeated sentences.
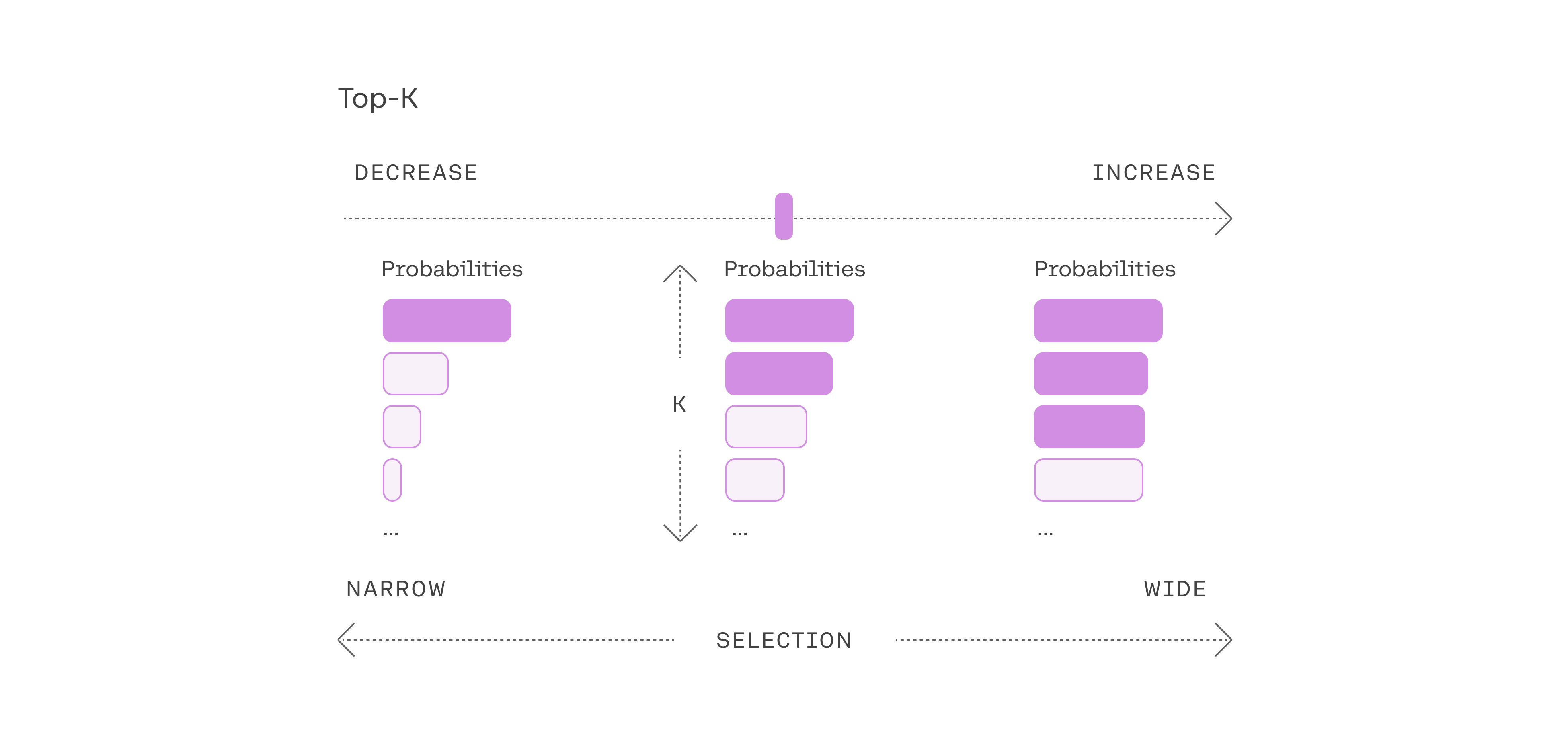
2. Pick from amongst the top tokens: top-k
Another commonly-used strategy is to sample from a shortlist of the top 3 tokens. This approach allows the other high-scoring tokens a chance of being picked. The randomness introduced by this sampling helps the quality of generation in a lot of scenarios.
More broadly, choosing the top three tokens means setting the top-k parameter to 3. Changing the top-k parameter sets the size of the shortlist the model samples from as it outputs each token. Setting top-k to 1 gives us greedy decoding.
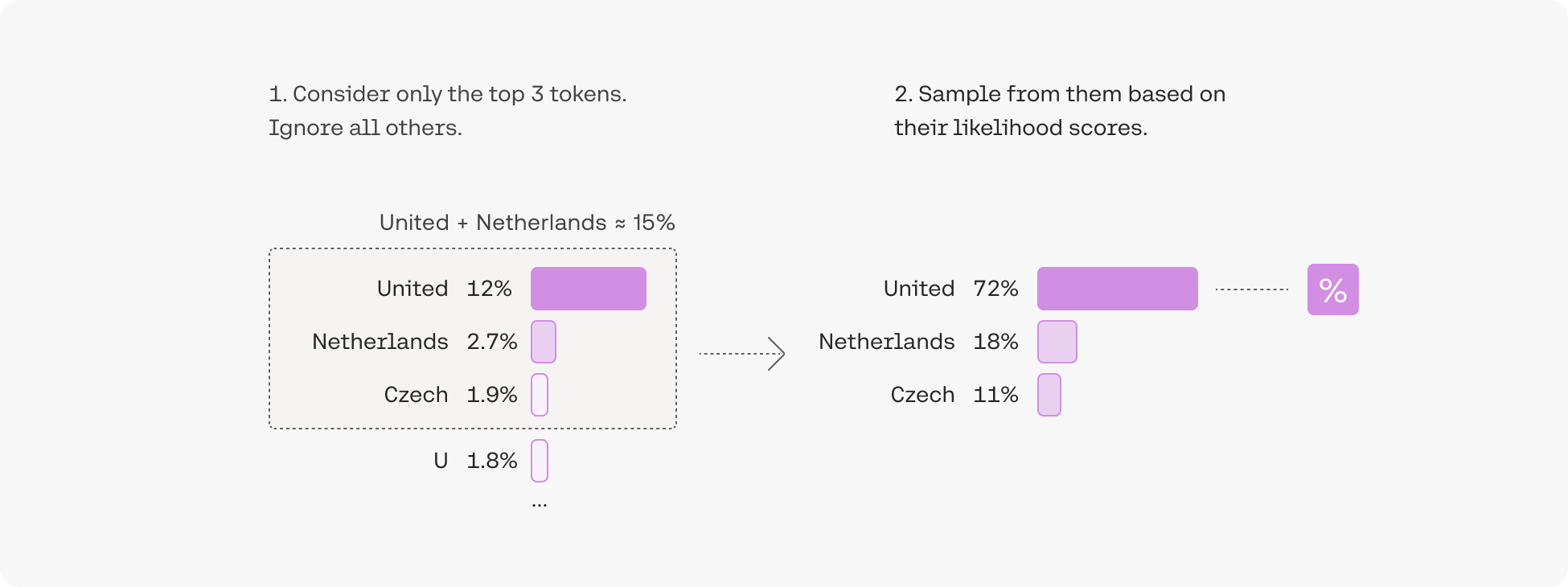
3. Pick from amongst the top tokens whose probabilities add up to 15%: top-p
The difficulty of selecting the best top-k value opens the door for a popular decoding strategy that dynamically sets the size of the shortlist of tokens. This method, called Nucleus Sampling, creates the shortlist by selecting the top tokens whose sum of likelihoods does not exceed a certain value. A toy example with a top-p value of 0.15 could look like this:
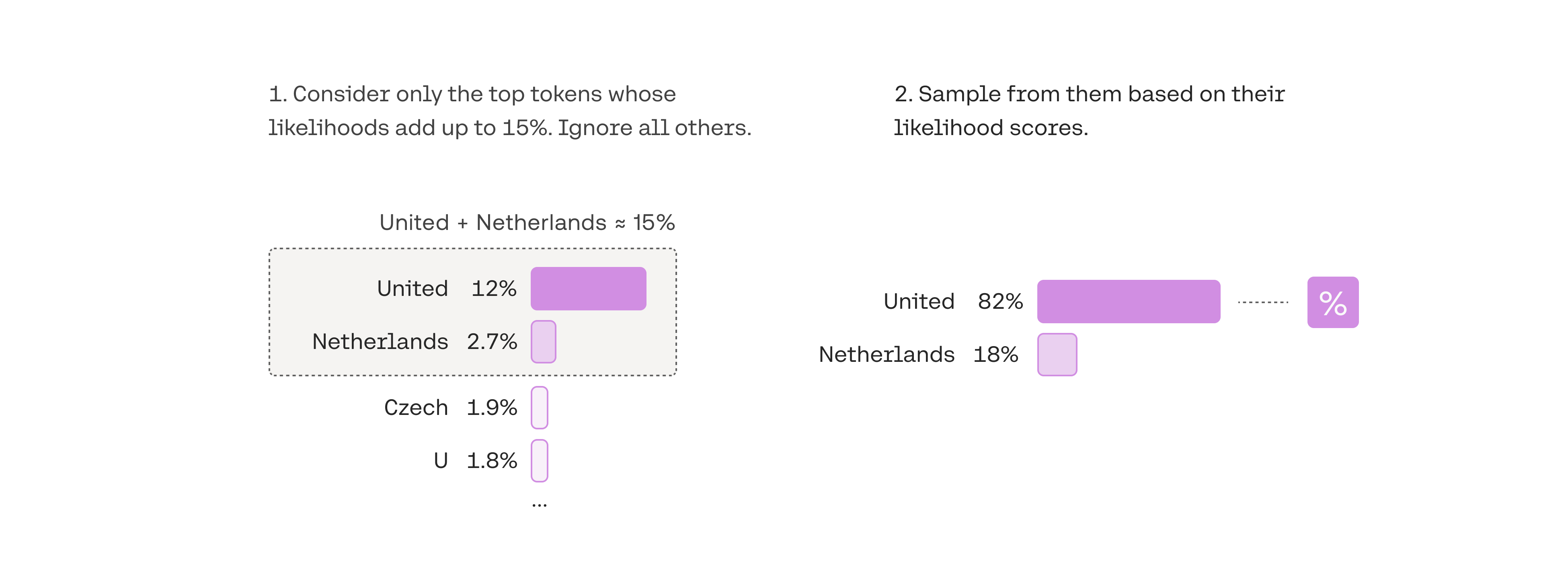
Top-p is usually set to a high value (like 0.75) with the purpose of limiting the long tail of low-probability tokens that may be sampled. We can use both top-k and top-p together. If both k and p are enabled, p acts after k.