Analyzing Hacker News with Cohere
Large language models give machines a vastly improved representation and understanding of language. These abilities give developers more options for content recommendation, analysis, and filtering.
In this notebook we take thousands of the most popular posts from Hacker News and demonstrate some of these functionalities:
- Given an existing post title, retrieve the most similar posts (nearest neighbor search using embeddings)
- Given a query that we write, retrieve the most similar posts
- Plot the archive of articles by similarity (where similar posts are close together and different ones are far)
- Cluster the posts to identify the major common themes
- Extract major keywords from each cluster so we can identify what the clsuter is about
- (Experimental) Name clusters with a generative language model
Setup
Let’s start by installing the tools we’ll need and then importing them.
1 !pip install cohere umap-learn altair annoy bertopic
Requirement already satisfied: cohere in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (5.1.5) Requirement already satisfied: umap-learn in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (0.5.5) Requirement already satisfied: altair in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (5.2.0) Requirement already satisfied: annoy in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (1.17.3) Requirement already satisfied: bertopic in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (0.16.0) Requirement already satisfied: httpx>=0.21.2 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from cohere) (0.27.0) Requirement already satisfied: pydantic>=1.9.2 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from cohere) (2.6.0) Requirement already satisfied: typing_extensions>=4.0.0 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from cohere) (4.10.0) Requirement already satisfied: numpy>=1.17 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from umap-learn) (1.24.3) Requirement already satisfied: scipy>=1.3.1 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from umap-learn) (1.11.1) Requirement already satisfied: scikit-learn>=0.22 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from umap-learn) (1.3.0) Requirement already satisfied: numba>=0.51.2 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from umap-learn) (0.57.0) Requirement already satisfied: pynndescent>=0.5 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from umap-learn) (0.5.12) Requirement already satisfied: tqdm in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from umap-learn) (4.65.0) Requirement already satisfied: jinja2 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from altair) (3.1.2) Requirement already satisfied: jsonschema>=3.0 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from altair) (4.17.3) Requirement already satisfied: packaging in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from altair) (23.2) Requirement already satisfied: pandas>=0.25 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from altair) (2.0.3) Requirement already satisfied: toolz in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from altair) (0.12.0) Requirement already satisfied: hdbscan>=0.8.29 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from bertopic) (0.8.33) Requirement already satisfied: sentence-transformers>=0.4.1 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from bertopic) (2.6.1) Requirement already satisfied: plotly>=4.7.0 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from bertopic) (5.9.0) Requirement already satisfied: cython<3,>=0.27 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from hdbscan>=0.8.29->bertopic) (0.29.37) Requirement already satisfied: joblib>=1.0 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from hdbscan>=0.8.29->bertopic) (1.2.0) Requirement already satisfied: anyio in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from httpx>=0.21.2->cohere) (3.5.0) Requirement already satisfied: certifi in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from httpx>=0.21.2->cohere) (2023.11.17) Requirement already satisfied: httpcore==1.* in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from httpx>=0.21.2->cohere) (1.0.2) Requirement already satisfied: idna in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from httpx>=0.21.2->cohere) (3.4) Requirement already satisfied: sniffio in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from httpx>=0.21.2->cohere) (1.2.0) Requirement already satisfied: h11<0.15,>=0.13 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from httpcore==1.*->httpx>=0.21.2->cohere) (0.14.0) Requirement already satisfied: attrs>=17.4.0 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from jsonschema>=3.0->altair) (22.1.0) Requirement already satisfied: pyrsistent!=0.17.0,!=0.17.1,!=0.17.2,>=0.14.0 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from jsonschema>=3.0->altair) (0.18.0) Requirement already satisfied: llvmlite<0.41,>=0.40.0dev0 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from numba>=0.51.2->umap-learn) (0.40.0) Requirement already satisfied: python-dateutil>=2.8.2 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from pandas>=0.25->altair) (2.8.2) Requirement already satisfied: pytz>=2020.1 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from pandas>=0.25->altair) (2023.3.post1) Requirement already satisfied: tzdata>=2022.1 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from pandas>=0.25->altair) (2023.3) Requirement already satisfied: tenacity>=6.2.0 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from plotly>=4.7.0->bertopic) (8.2.2) Requirement already satisfied: annotated-types>=0.4.0 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from pydantic>=1.9.2->cohere) (0.6.0) Requirement already satisfied: pydantic-core==2.16.1 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from pydantic>=1.9.2->cohere) (2.16.1) Requirement already satisfied: threadpoolctl>=2.0.0 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from scikit-learn>=0.22->umap-learn) (2.2.0) Requirement already satisfied: transformers<5.0.0,>=4.32.0 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from sentence-transformers>=0.4.1->bertopic) (4.39.3) Requirement already satisfied: torch>=1.11.0 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from sentence-transformers>=0.4.1->bertopic) (2.2.2) Requirement already satisfied: huggingface-hub>=0.15.1 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from sentence-transformers>=0.4.1->bertopic) (0.22.2) Requirement already satisfied: Pillow in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from sentence-transformers>=0.4.1->bertopic) (10.0.1) Requirement already satisfied: MarkupSafe>=2.0 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from jinja2->altair) (2.1.1) Requirement already satisfied: filelock in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from huggingface-hub>=0.15.1->sentence-transformers>=0.4.1->bertopic) (3.9.0) Requirement already satisfied: fsspec>=2023.5.0 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from huggingface-hub>=0.15.1->sentence-transformers>=0.4.1->bertopic) (2024.3.1) Requirement already satisfied: pyyaml>=5.1 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from huggingface-hub>=0.15.1->sentence-transformers>=0.4.1->bertopic) (6.0) Requirement already satisfied: requests in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from huggingface-hub>=0.15.1->sentence-transformers>=0.4.1->bertopic) (2.31.0) Requirement already satisfied: six>=1.5 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from python-dateutil>=2.8.2->pandas>=0.25->altair) (1.16.0) Requirement already satisfied: sympy in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from torch>=1.11.0->sentence-transformers>=0.4.1->bertopic) (1.11.1) Requirement already satisfied: networkx in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from torch>=1.11.0->sentence-transformers>=0.4.1->bertopic) (3.1) Requirement already satisfied: regex!=2019.12.17 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from transformers<5.0.0,>=4.32.0->sentence-transformers>=0.4.1->bertopic) (2022.7.9) Requirement already satisfied: tokenizers<0.19,>=0.14 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from transformers<5.0.0,>=4.32.0->sentence-transformers>=0.4.1->bertopic) (0.15.2) Requirement already satisfied: safetensors>=0.4.1 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from transformers<5.0.0,>=4.32.0->sentence-transformers>=0.4.1->bertopic) (0.4.2) Requirement already satisfied: charset-normalizer<4,>=2 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from requests->huggingface-hub>=0.15.1->sentence-transformers>=0.4.1->bertopic) (3.3.2) Requirement already satisfied: urllib3<3,>=1.21.1 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from requests->huggingface-hub>=0.15.1->sentence-transformers>=0.4.1->bertopic) (1.26.18) Requirement already satisfied: mpmath>=0.19 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from sympy->torch>=1.11.0->sentence-transformers>=0.4.1->bertopic) (1.3.0)
1 import cohere 2 import numpy as np 3 import pandas as pd 4 import umap 5 import altair as alt 6 from annoy import AnnoyIndex 7 import warnings 8 from sklearn.cluster import KMeans 9 from sklearn.feature_extraction.text import CountVectorizer 10 from bertopic.vectorizers import ClassTfidfTransformer 11 12 warnings.filterwarnings('ignore') 13 pd.set_option('display.max_colwidth', None)
Fill in your Cohere API key in the next cell. To do this, begin by signing up to Cohere (for free!) if you haven’t yet. Then get your API key here.
1 co = cohere.Client("COHERE_API_KEY") # Insert your Cohere API key
Dataset: Top 3,000 Ask HN posts
We will use the top 3,000 posts from the Ask HN section of Hacker News. We provide a CSV containing the posts.
1 df = pd.read_csv('https://storage.googleapis.com/cohere-assets/blog/text-clustering/data/askhn3k_df.csv', index_col=0) 2 3 print(f'Loaded a DataFrame with {len(df)} rows')
Loaded a DataFrame with 3000 rows
1 df.head()
| title | url | text | dead | by | score | time | timestamp | type | id | parent | descendants | ranking | deleted | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | I’m a software engineer going blind, how should I prepare? | NaN | I'm a 24 y/o full stack engineer (I know some of you are rolling your eyes right now, just highlighting that I have experience on frontend apps as well as backend architecture). I've been working professionally for ~7 years building mostly javascript projects but also some PHP. Two years ago I was diagnosed with a condition called "Usher's Syndrome" - characterized by hearing loss, balance issues, and progressive vision loss.<p>I know there are blind software engineers out there. My main questions are:<p>- Are there blind frontend engineers?<p>- What kinds of software engineering lend themselves to someone with limited vision? Backend only?<p>- Besides a screen reader, what are some of the best tools for building software with limited vision?<p>- Does your company employ blind engineers? How well does it work? What kind of engineer are they?<p>I'm really trying to get ahead of this thing and prepare myself as my vision is degrading rather quickly. I'm not sure what I can do if I can't do SE as I don't have any formal education in anything. I've worked really hard to get to where I am and don't want it to go to waste.<p>Thank you for any input, and stay safe out there!<p>Edit:<p>Thank you all for your links, suggestions, and moral support, I really appreciate it. Since my diagnosis I've slowly developed a crippling anxiety centered around a feeling that I need to figure out the rest of my life before it's too late. I know I shouldn't think this way but it is hard not to. I'm very independent and I feel a pressure to "show up." I will look into these opportunities mentioned and try to get in touch with some more members of the blind engineering community. | NaN | zachrip | 3270 | 1587332026 | 2020-04-19 21:33:46+00:00 | story | 22918980 | NaN | 473.0 | NaN | NaN |
| 1 | Am I the longest-serving programmer – 57 years and counting? | NaN | In May of 1963, I started my first full-time job as a computer programmer for Mitchell Engineering Company, a supplier of steel buildings. At Mitchell, I developed programs in Fortran II on an IBM 1620 mostly to improve the efficiency of order processing and fulfillment. Since then, all my jobs for the past 57 years have involved computer programming. I am now a data scientist developing cloud-based big data fraud detection algorithms using machine learning and other advanced analytical technologies. Along the way, I earned a Master’s in Operations Research and a Master’s in Management Science, studied artificial intelligence for 3 years in a Ph.D. program for engineering, and just two years ago I received Graduate Certificates in Big Data Analytics from the schools of business and computer science at a local university (FAU). In addition, I currently hold the designation of Certified Analytics Professional (CAP). At 74, I still have no plans to retire or to stop programming. | NaN | genedangelo | 2634 | 1590890024 | 2020-05-31 01:53:44+00:00 | story | 23366546 | NaN | 531.0 | NaN | NaN |
| 2 | Is S3 down? | NaN | I'm getting<p>{\n "errorCode" : "InternalError"\n}<p>When I attempt to use the AWS Console to view s3 | NaN | iamdeedubs | 2589 | 1488303958 | 2017-02-28 17:45:58+00:00 | story | 13755673 | NaN | 1055.0 | NaN | NaN |
| 3 | What tech job would let me get away with the least real work possible? | NaN | Hey HN,<p>I'll probably get a lot of flak for this. Sorry.<p>I'm an average developer looking for ways to work as little as humanely possible.<p>The pandemic made me realize that I do not care about working anymore. The software I build is useless. Time flies real fast and I have to focus on my passions (which are not monetizable).<p>Unfortunately, I require shelter, calories and hobby materials. Thus the need for some kind of job.<p>Which leads me to ask my fellow tech workers, what kind of job (if any) do you think would fit the following requirements :<p>- No / very little involvement in the product itself (I do not care.)<p>- Fully remote (You can't do much when stuck in the office. Ideally being done in 2 hours in the morning then chilling would be perfect.)<p>- Low expectactions / vague job description.<p>- Salary can be on the lower side.<p>- No career advancement possibilities required. Only tech, I do not want to manage people.<p>- Can be about helping other developers, setting up infrastructure/deploy or pure data management since this is fun.<p>I think the only possible jobs would be some kind of backend-only dev or devops/sysadmin work. But I'm not sure these exist anymore, it seems like you always end up having to think about the product itself. Web dev jobs always required some involvement in the frontend.<p>Thanks for any advice (or hate, which I can't really blame you for). | NaN | lmueongoqx | 2022 | 1617784863 | 2021-04-07 08:41:03+00:00 | story | 26721951 | NaN | 1091.0 | NaN | NaN |
| 4 | What books changed the way you think about almost everything? | NaN | I was reflecting today about how often I think about Freakonomics. I don't study it religiously. I read it one time more than 10 years ago. I can only remember maybe a single specific anecdote from the book. And yet the simple idea that basically every action humans take can be traced back to an incentive has fundamentally changed the way I view the world. Can anyone recommend books that have had a similar impact on them? | NaN | anderspitman | 2009 | 1549387905 | 2019-02-05 17:31:45+00:00 | story | 19087418 | NaN | 1165.0 | NaN | NaN |
We calculate the embeddings using Cohere’s embed-v4.0 model. The resulting embeddings matrix has 3,000 rows (one for each post) and 1024 columns (meaning each post title is represented with a 1024-dimensional embedding).
1 batch_size = 90 2 3 embeds_list = [] 4 for i in range(0, len(df), batch_size): 5 batch = df[i : min(i + batch_size, len(df))] 6 texts = list(batch["title"]) 7 embs_batch = co.embed( 8 texts=texts, model="embed-v4.0", input_type="search_document" 9 ).embeddings 10 embeds_list.extend(embs_batch) 11 12 embeds = np.array(embeds_list) 13 embeds.shape
(3000, 1024)
Building a semantic search index
For nearest-neighbor search, we can use the open-source Annoy library. Let’s create a semantic search index and feed it all the embeddings.
1 search_index = AnnoyIndex(embeds.shape[1], 'angular') 2 for i in range(len(embeds)): 3 search_index.add_item(i, embeds[i]) 4 5 search_index.build(10) # 10 trees 6 search_index.save('askhn.ann')
True
1- Given an existing post title, retrieve the most similar posts (nearest neighbor search using embeddings)
We can query neighbors of a specific post using get_nns_by_item.
1 example_id = 50 2 3 similar_item_ids = search_index.get_nns_by_item(example_id, 4 10, # Number of results to retrieve 5 include_distances=True) 6 results = pd.DataFrame(data={'post titles': df.iloc[similar_item_ids[0]]['title'], 7 'distance': similar_item_ids[1]}).drop(example_id) 8 9 print(f"Query post:'{df.iloc[example_id]['title']}'\nNearest neighbors:") 10 results
Query post:'Pick startups for YC to fund' Nearest neighbors:
| post titles | distance | |
|---|---|---|
| 2991 | Best Bank for Startups? | 0.883494 |
| 2910 | Who’s looking for a cofounder? | 0.885087 |
| 31 | What startup/technology is on your ‘to watch’ list? | 0.887212 |
| 685 | What startup/technology is on your ‘to watch’ list? | 0.887212 |
| 2123 | Who is seeking a cofounder? | 0.889451 |
| 727 | Agriculture startups doing interesting work? | 0.899192 |
| 2972 | How should I evaluate a startup as I job hunt? | 0.901621 |
| 2589 | What methods do you use to gain early customers for your startup? | 0.903065 |
| 2708 | Is there VC appetite for defense related startups? | 0.904016 |
2- Given a query that we write, retrieve the most similar posts
We’re not limited to searching using existing items. If we get a query, we can embed it and find its nearest neighbors from the dataset.
1 query = "How can I improve my knowledge of calculus?" 2 3 query_embed = co.embed(texts=[query], 4 model="embed-v4.0", 5 truncate="RIGHT", 6 input_type="search_query").embeddings 7 8 similar_item_ids = search_index.get_nns_by_vector(query_embed[0], 10, include_distances=True) 9 10 results = pd.DataFrame(data={'texts': df.iloc[similar_item_ids[0]]['title'], 11 'distance': similar_item_ids[1]}) 12 print(f"Query:'{query}'\nNearest neighbors:") 13 results
Query:'How can I improve my knowledge of calculus?' Nearest neighbors:
| texts | distance | |
|---|---|---|
| 2457 | How do I improve my command of mathematical language? | 0.931286 |
| 1235 | How to learn new things better? | 1.024635 |
| 145 | How to self-learn math? | 1.044135 |
| 1317 | How can I learn to read mathematical notation? | 1.050976 |
| 910 | How Do You Learn? | 1.061253 |
| 2432 | How did you learn math notation? | 1.070800 |
| 1994 | How do I become smarter? | 1.083434 |
| 1529 | How do you personally learn? | 1.086088 |
| 796 | How do you keep improving? | 1.087251 |
| 1286 | How do I learn drawing? | 1.088468 |
3- Plot the archive of articles by similarity
What if we want to browse the archive instead of only searching it? Let’s plot all the questions in a 2D chart so you’re able to visualize the posts in the archive and their similarities.
1 reducer = umap.UMAP(n_neighbors=100) 2 umap_embeds = reducer.fit_transform(embeds)
1 df['x'] = umap_embeds[:,0] 2 df['y'] = umap_embeds[:,1] 3 4 chart = alt.Chart(df).mark_circle(size=60).encode( 5 x=#'x', 6 alt.X('x', 7 scale=alt.Scale(zero=False), 8 axis=alt.Axis(labels=False, ticks=False, domain=False) 9 ), 10 y= 11 alt.Y('y', 12 scale=alt.Scale(zero=False), 13 axis=alt.Axis(labels=False, ticks=False, domain=False) 14 ), 15 tooltip=['title'] 16 ).configure(background="#FDF7F0" 17 ).properties( 18 width=700, 19 height=400, 20 title='Ask HN: top 3,000 posts' 21 ) 22 23 chart.interactive()
4- Cluster the posts to identify the major common themes
Let’s proceed to cluster the embeddings using KMeans from scikit-learn.
1 n_clusters = 8 2 3 kmeans_model = KMeans(n_clusters=n_clusters, random_state=0) 4 classes = kmeans_model.fit_predict(embeds)
5- Extract major keywords from each cluster so we can identify what the cluster is about
1 documents = df['title'] 2 documents = pd.DataFrame({"Document": documents, 3 "ID": range(len(documents)), 4 "Topic": None}) 5 documents['Topic'] = classes 6 documents_per_topic = documents.groupby(['Topic'], as_index=False).agg({'Document': ' '.join}) 7 count_vectorizer = CountVectorizer(stop_words="english").fit(documents_per_topic.Document) 8 count = count_vectorizer.transform(documents_per_topic.Document) 9 words = count_vectorizer.get_feature_names_out()
1 ctfidf = ClassTfidfTransformer().fit_transform(count).toarray() 2 words_per_class = {label: [words[index] for index in ctfidf[label].argsort()[-10:]] for label in documents_per_topic.Topic} 3 df['cluster'] = classes 4 df['keywords'] = df['cluster'].map(lambda topic_num: ", ".join(np.array(words_per_class[topic_num])[:]))
Plot with clusters and keywords information
We can now plot the documents with their clusters and keywords
1 selection = alt.selection_multi(fields=['keywords'], bind='legend') 2 3 chart = alt.Chart(df).transform_calculate( 4 url='https://news.ycombinator.com/item?id=' + alt.datum.id 5 ).mark_circle(size=60, stroke='#666', strokeWidth=1, opacity=0.3).encode( 6 x=#'x', 7 alt.X('x', 8 scale=alt.Scale(zero=False), 9 axis=alt.Axis(labels=False, ticks=False, domain=False) 10 ), 11 y= 12 alt.Y('y', 13 scale=alt.Scale(zero=False), 14 axis=alt.Axis(labels=False, ticks=False, domain=False) 15 ), 16 href='url:N', 17 color=alt.Color('keywords:N', 18 legend=alt.Legend(columns=1, symbolLimit=0, labelFontSize=14) 19 ), 20 opacity=alt.condition(selection, alt.value(1), alt.value(0.2)), 21 tooltip=['title', 'keywords', 'cluster', 'score', 'descendants'] 22 ).properties( 23 width=800, 24 height=500 25 ).add_selection( 26 selection 27 ).configure_legend(labelLimit= 0).configure_view( 28 strokeWidth=0 29 ).configure(background="#FDF7F0").properties( 30 title='Ask HN: Top 3,000 Posts' 31 ) 32 chart.interactive()
6- (Experimental) Naming clusters with a generative language model
While the extracted keywords do add a lot of information to help us identify the clusters at a glance, we should be able to have a generative model look at these keywords and suggest a name. So far I have reasonable results from a prompt that looks like this:
The common theme of the following words: books, book, read, the, you, are, what, best, in, your is that they all relate to favorite books to read. --- The common theme of the following words: startup, company, yc, failed is that they all relate to startup companies and their failures. --- The common theme of the following words: freelancer, wants, hired, be, who, seeking, to, 2014, 2020, april is that they all relate to hiring for a freelancer to join the team of a startup. --- The common theme of the following words: <insert keywords here> is that they all relate to
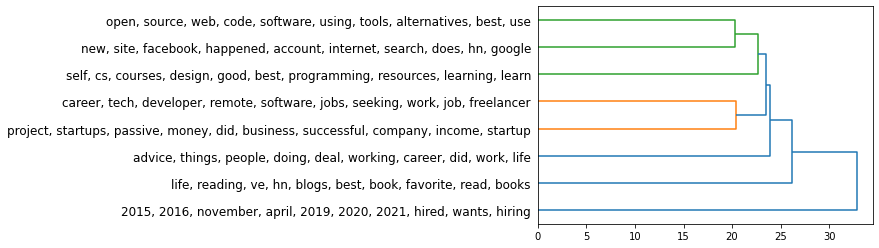
There’s a lot of room for improvement though. I’m really excited by this use case because it adds so much information. Imagine if the in the following tree of topics, you assigned each cluster an intelligible name. Then imagine if you assigned each branching a name as well
We can’t wait to see what you start building! Share your projects or find support on our Discord server.