Multilingual Semantic Search
Guest Lecturer
This chapter and the next one have been created by Amr Kayid, from Cohere.
Introduction
This exercise will show you how to build a multilingual movie search application. When complete, users just describe the movie they would like to watch and the app will suggest movies that are a perfect match for them. They can describe a movie in a variety of languages since the app will perform a multilingual search.
The steps to build the Multilingual Movie Search app are:
- Step 1: Gather movie data
- Step 2: Build a user interface to get movie descriptions
- Step 3: Filter movies by language
- Step 4: Embed the movie description
- Step 5: Calculate movie similarity
- Step 6: Show similar movies
- Step 7: Setup and run
Read on for more details on each of these steps.
Github Repo and Files
The repository for this project is here, and we encourage you to follow the code along with this tutorial.
For the setup, please refer to the Setting Up chapter at the beginning of this module.
The project code contains the following files:
- The
movies.pyfile contains the code of the movie recommender. - The
utils.pyfile provides some utilities. - The
requirements.txtfile lists the project dependencies. - The
data/the_movies_with_embeddings.jsonfile contains a movie dataset and precomputed embeddings of each movie’s description. - The
Makefilebuilds a virtual environment for the project.
You can use the Makefile to create a virtual environment with the required libraries and dependencies using the make command or just install the necessary dependencies by running the pip install -r requirements.txt command either in a notebook or in your local environment.
You should also set up your .env file at the root of your directory to hold your Cohere API key. To get the API key, log in to the Cohere dashboard and navigate to the API Keys section. Keep this information private!
Step 1: Gather Movie Data
To begin, we’ll build a movie database containing fields for the title, description, original language, and more.
You can get this data from a variety of sources, such as the Internet Movie Database (IMDB), but this tutorial will use a premade JSON file (the_movies_with_embeddings.json), which already contains information from nearly 45,000 movies. This file also includes pre-calculated embeddings of each movie’s description. We’ll see how to embed a movie description later on.
The code below builds the movie database. The function setup_movie_database defines the fields, cleans the data by removing null values, and then fills in empty fields, adds a movie ID field, and returns the movie database and the embeddings representing movie descriptions. The movies_df and candidates variables store the movie database and the embeddings, respectively.
Running this function should give the following output: “Movie database ready! You have 44497 movies in your database in 112 different languages.”
Step 2: Build a User Interface to Get Movie Descriptions
In this step, we’ll use the Streamlit Python library to build an interactive and user-friendly interface in your browser. (If you’d like to learn more about deploying in Streamlit, please check this chapter in the deployment module, where you can learn all the details).
To improve the interface design, use the streamlit_header_and_footer_setup function implemented in the utils.py file. This will set up a header and footer for your app, apply custom CSS to style both, and incorporate the Cohere brand logo into the header.
Next, title the app “Movies Search and Recommendation.” The st.text_input function will create a text input box for the user to enter a movie description.
Step 3: Filter Movies by Language
Next, we’ll create an expandable section called Search Fields, Expand me! in your interface. This section will include two fields:
A slider for the user to select the number of movies to show in the app
A drop-down menu that displays the available movie languages in the database, allowing the user to choose multiple desired languages for movies
The following code also defines the movie data fields to display in the interface.
Step 4: Embed the Movie Description
In this step, we’ll use the Cohere embed endpoint to embed a movie description provided by the user. Start by setting up the Cohere API with your API key.
Use the embed-multilingual-v2.0 model to embed the movie description. If the text is longer than 4096 tokens, the co.embed function (truncate parameter) will truncate it for you. The co.embed function will convert the query_text into an embedding, which is a 768-dimensional vector of floats that uniquely represents a movie description.
Text that means the same thing in different languages will be close together in the embedding space. To achieve this, Cohere’s embed endpoint uses a multilingual model to represent text in a language-agnostic way.
Step 5: Calculate Movie Similarity
To find the movies that are most similar to a movie description, we’ll perform the dot product of the resultant vectors in the get_similarity function. This function calculates the similarity between a target movie description and a set of candidate movie descriptions in the embedding space. This step is crucial and determines the quality of the recommendation system.
We’ll get the highest cosine similarity scores using the torch.topk function. Notice that the PyTorch library functions expect tensors as input. Use torchify lambda function to convert your arrays to tensors.
Step 6: Show Similar Movies
Now, it’s time to display the most similar movies to a given movie description. We’ll process the outputs of the get_similarity function to create a dictionary called similar_results. The dictionary maps indices to a nested dictionary, where each dictionary contains movie information.
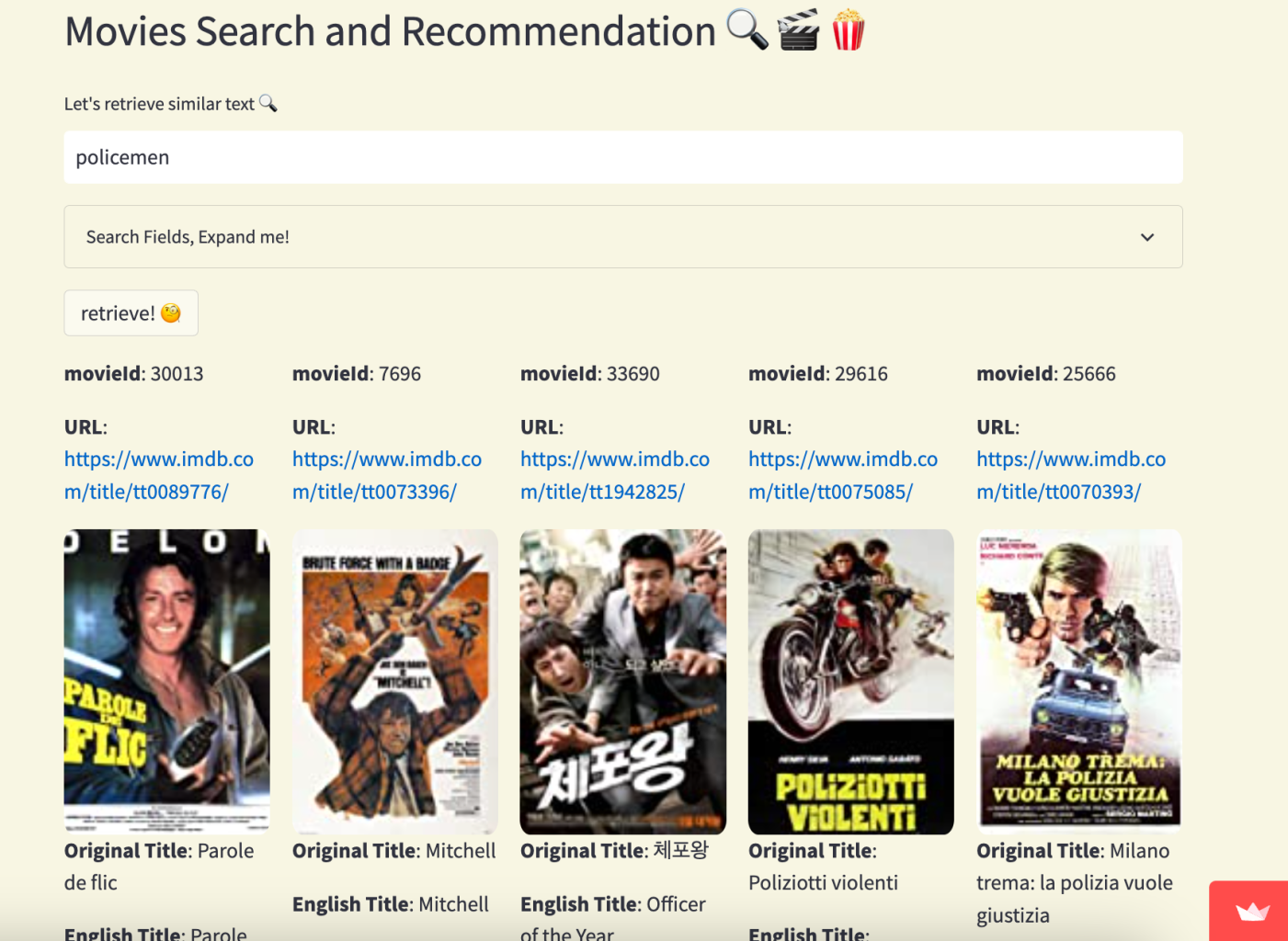
Use the Streamlit library to display the movies as a grid with five columns per row. Each entry in the grid shows the movie ID, URL, cover image, title, overview, genres, release date, language, and distance. If any of the values are missing or cannot be retrieved, the code moves on to the next movie.
Step 7: Set Up and Run
To run the movie recommendation app, open a new terminal and execute streamlit run movies.py. This gives you a link in your terminal to view your app in your browser.
Input a movie description such as: “A hard-nosed cop reluctantly teams up with a wise-cracking criminal, temporarily paroled to him, to track down a killer.”
Select English, Romanian, and Spanish language in the expandable section. You should get the following.
Now, use DeepL to translate the movie description to Korean or a different language. You should get the movie 48 Hrs. in your outputs since you’re using the multilingual model.
Conclusion
By following the steps in this article, you’ve created a movie recommendation app that recommends movies based on a description written in any language. To accomplish this, you used Cohere’s multilingual model, which embeds movie descriptions into a language-invariant embedding space, capturing similarities between movies regardless of language.