
Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG) is a method for generating text using additional information fetched from an external data source, which can greatly increase the accuracy of the response. When used in conjunction with a Command, Command R, or Command R+, the Chat API makes it easy to generate text that is grounded on supplementary information.
The code snippet below, for example, will produce a grounded answer to "Where do the tallest penguins live?", along with inline citations based on the provided documents.
Request
import cohere
co = cohere.Client(api_key="<YOUR API KEY>")
co.chat(
model="command-r-plus",
message="Where do the tallest penguins live?",
documents=[
{"title": "Tall penguins", "snippet": "Emperor penguins are the tallest."},
{"title": "Penguin habitats", "snippet": "Emperor penguins only live in Antarctica."},
{"title": "What are animals?", "snippet": "Animals are different from plants."}
])
Response
{
"text": "The tallest penguins, Emperor penguins, live in Antarctica.",
"citations": [
{"start": 22, "end": 38, "text": "Emperor penguins", "document_ids": ["doc_0"]},
{"start": 48, "end": 59, "text": "Antarctica.", "document_ids": ["doc_1"]}
],
"documents": [
{"id": "doc_0", "title": "Tall penguins", "snippet": "Emperor penguins are the tallest.", "url": ""},
{"id": "doc_1", "title": "Penguin habitats", "snippet": "Emperor penguins only live in Antarctica.", "url": ""}
]
}
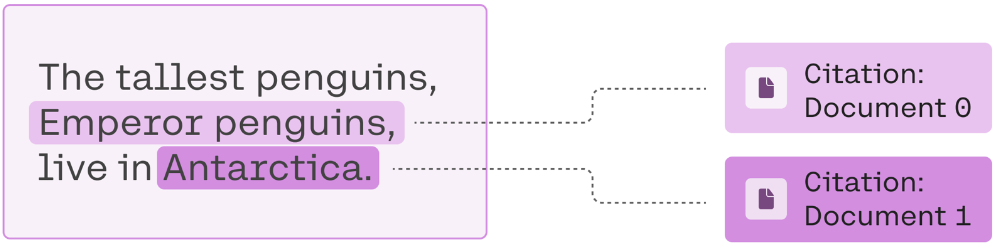
The resulting generation is"The tallest penguins, Emperor penguins, live in Antarctica". The model was able to combine partial information from multiple sources and ignore irrelevant documents to arrive at the full answer.
Nice 🐧❄️!
The response also includes inline citations that reference the first two documents, since they hold the answers.
As you will learn in the following section, the Chat API will also assist you with generating search queries to fetch documents from a data source.
You can find more code and context in this colab notebook.
Three steps of RAG
The RAG workflow generally consists of 3 steps:
- Generating search queries for finding relevant documents. What does the model recommend looking up before answering this question?
- Fetching relevant documents from an external data source using the generated search queries. Performing a search to find some relevant information.
- Generating a response with inline citations using the fetched documents. Using the acquired knowledge to produce an educated answer.
Example: Using RAG to identify the definitive 90s boy band
In this section, we will use the three step RAG workflow to finally settle the score between the notorious boy bands Backstreet Boys and NSYNC. We ask the model to provide an informed answer to the question "Who is more popular: Nsync or Backstreet Boys?"
Step 1: Generating search queries
Calling the Chat API with the search_queries_only parameter set to True will return a list of search queries. In the example below, we ask the model to suggest some search queries that would be useful when answering the question.
Request
import cohere
co = cohere.Client(api_key="<YOUR API KEY>")
co.chat(
model="command-r-plus",
message="Who is more popular: Nsync or Backstreet Boys?",
search_queries_only=True
)
Response
{
"is_search_required": true,
"search_queries": [
{"text": "Nsync popularity", "generation_id": "b560dd68-743e-4c32-98a2-a9b7e3e96861"},
{"text": "Backstreet Boys popularity", "generation_id": "b560dd68-743e-4c32-98a2-a9b7e3e96861"}
]
}
Indeed, to generate a factually accurate answer to the question "Who is more popular: Nsync or Backstreet Boys?", looking up Nsync popularity and Backstreet Boys popularity first would be helpful.
Step 2: Fetching relevant documents
The next step is to fetch documents from the relevant data source using the generated search queries. For example, to answer the question about the two pop sensations NSYNC and Backstreet Boys, one might want to use an API from a web search engine, and fetch the contents of the websites listed at the top of the search results.
We won't go into details of fetching data in this guide, since it's very specific to the search API you're querying. However we should mention that breaking up long documents into smaller ones first (1-2 paragraphs) will help you not go over the context limit. When trying to stay within the context length limit, you might need to omit some of the documents from the request. To make sure that only the least relevant documents are omitted, we recommend using the Rerank endpoint endpoint which will sort the documents by relevancy to the query. The lowest ranked documents are the ones you should consider dropping first.
Step 3: Generating a response
In the final step, we will be calling the Chat API again, but this time passing along the documents you acquired in Step 2. A document object is a dictionary containing the content and the metadata of the text. We recommend using a few descriptive keys such as "title", "snippet", or "last updated" and only including semantically relevant data. The keys and the values will be formatted into the prompt and passed to the model.
Request
import cohere
co = cohere.Client(api_key="<YOUR API KEY>")
co.chat(
model="command-r-plus",
message="Who is more popular: Nsync or Backstreet Boys?",
documents=[
{
"title": "CSPC: Backstreet Boys Popularity Analysis - ChartMasters",
"snippet": "↓ Skip to Main Content\n\nMusic industry – One step closer to being accurate\n\nCSPC: Backstreet Boys Popularity Analysis\n\nHernán Lopez Posted on February 9, 2017 Posted in CSPC 72 Comments Tagged with Backstreet Boys, Boy band\n\nAt one point, Backstreet Boys defined success: massive albums sales across the globe, great singles sales, plenty of chart topping releases, hugely hyped tours and tremendous media coverage.\n\nIt is true that they benefited from extraordinarily good market conditions in all markets. After all, the all-time record year for the music business, as far as revenues in billion dollars are concerned, was actually 1999. That is, back when this five men group was at its peak."
},
{
"title": "CSPC: NSYNC Popularity Analysis - ChartMasters",
"snippet": "↓ Skip to Main Content\n\nMusic industry – One step closer to being accurate\n\nCSPC: NSYNC Popularity Analysis\n\nMJD Posted on February 9, 2018 Posted in CSPC 27 Comments Tagged with Boy band, N'Sync\n\nAt the turn of the millennium three teen acts were huge in the US, the Backstreet Boys, Britney Spears and NSYNC. The latter is the only one we haven’t study so far. It took 15 years and Adele to break their record of 2,4 million units sold of No Strings Attached in its first week alone.\n\nIt wasn’t a fluke, as the second fastest selling album of the Soundscan era prior 2015, was also theirs since Celebrity debuted with 1,88 million units sold."
},
{
"title": "CSPC: Backstreet Boys Popularity Analysis - ChartMasters",
"snippet": " 1997, 1998, 2000 and 2001 also rank amongst some of the very best years.\n\nYet the way many music consumers – especially teenagers and young women’s – embraced their output deserves its own chapter. If Jonas Brothers and more recently One Direction reached a great level of popularity during the past decade, the type of success achieved by Backstreet Boys is in a completely different level as they really dominated the business for a few years all over the world, including in some countries that were traditionally hard to penetrate for Western artists.\n\nWe will try to analyze the extent of that hegemony with this new article with final results which will more than surprise many readers."
},
{
"title": "CSPC: NSYNC Popularity Analysis - ChartMasters",
"snippet": " Was the teen group led by Justin Timberlake really that big? Was it only in the US where they found success? Or were they a global phenomenon?\n\nAs usual, I’ll be using the Commensurate Sales to Popularity Concept in order to relevantly gauge their results. This concept will not only bring you sales information for all NSYNC‘s albums, physical and download singles, as well as audio and video streaming, but it will also determine their true popularity. If you are not yet familiar with the CSPC method, the next page explains it with a short video. I fully recommend watching the video before getting into the sales figures."
}
])
Response
{
"text": "Both the Backstreet Boys and *NSYNC enjoyed immense popularity during the late 1990s and early 2000s. \n\nThe Backstreet Boys, with massive album sales, chart-topping releases and highly successful tours, dominated the music industry for several years worldwide. They sold millions of copies of their albums No Strings Attached and Celebrity, breaking even the sales records of Adele and ranking as the second-fastest-selling album of the Soundscan era before 2015. \n\n*NSYNC, led by Justin Timberlake, also achieved tremendous success, selling millions of copies of their albums and finding popularity not just in the US but globally. \n\nHowever, when comparing the two groups, the extent of the Backstreet Boys' success puts them at a significantly higher level. They dominated the industry for several years, achieving unparalleled success in traditionally non-Western markets. Therefore, I can conclude that the Backstreet Boys are the more popular group.",
"citations": [
{ "start": 44, "end": 101, "text": "immense popularity during the late 1990s and early 2000s.", "document_ids": ["doc_0", "doc_1", "doc_2"]},
{ "start": 130, "end": 201, "text": "massive album sales, chart-topping releases and highly successful tours", "document_ids": ["doc_0"]},
// ...
],
"documents": [
{ "id": "doc_0", "snippet": "↓ Skip to Main Content\n\nMusic industry – One step closer to being accurate\n\nCSPC: Backstreet Boys Popularity Analysis\n\nHernán Lopez Posted on February 9, 2017 Posted in CSPC 72 Comments Tagged with Backstreet Boys, Boy band\n\nAt one point, Backstreet Boys defined success: massive albums sales across the globe, great singles sales, plenty of chart topping releases, hugely hyped tours and tremendous media coverage.\n\nIt is true that they benefited from extraordinarily good market conditions in all markets. After all, the all-time record year for the music business, as far as revenues in billion dollars are concerned, was actually 1999. That is, back when this five men group was at its peak.", "title": "CSPC: Backstreet Boys Popularity Analysis - ChartMasters"},
{ "id": "doc_1", "snippet": "↓ Skip to Main Content\n\nMusic industry – One step closer to being accurate\n\nCSPC: NSYNC Popularity Analysis\n\nMJD Posted on February 9, 2018 Posted in CSPC 27 Comments Tagged with Boy band, N'Sync\n\nAt the turn of the millennium three teen acts were huge in the US, the Backstreet Boys, Britney Spears and NSYNC. The latter is the only one we haven’t study so far. It took 15 years and Adele to break their record of 2,4 million units sold of No Strings Attached in its first week alone.\n\nIt wasn’t a fluke, as the second fastest selling album of the Soundscan era prior 2015, was also theirs since Celebrity debuted with 1,88 million units sold.", "title": "CSPC: NSYNC Popularity Analysis - ChartMasters"},
//...
]
}
Not only will we discover that the Backstreet Boys were the more popular band, but the model can also Tell Me Why, by providing details supported by citations.
Connectors
As an alternative to manually implementing the 3 step workflow, the Chat API offers a 1-line solution for RAG using Connectors. In the example below, specifying the web-search connector will generate search queries, use them to conduct an internet search and use the results to inform the model and produce an answer.
Request
import cohere
co = cohere.Client(api_key="<YOUR API KEY>")
co.chat(
model="command-r-plus",
message="Who is more popular: Nsync or Backstreet Boys?",
connectors=[{"id": "web-search"}])
Response
{
"text": "The Backstreet Boys have sold over 100 million records worldwide, making them the best-selling boy band of all time, and one of the world's best-selling music artists. They are the only boy band to have their first ten albums reach the top 10 on the Billboard 200. \n\n'NSYNC sold over 2.4 million copies in the United States during its first week of release, setting the record as the first album to have sold more than two million copies in a single week since the chart adopted Nielsen SoundScan data in May 1991. Their best-selling album, No Strings Attached sold over 11 million copies in the US alone. \n\nIt's clear that both bands have enjoyed enormous commercial success, however, based on the available sales data, The Backstreet Boys take the crown as the better-selling band of the two.",
"search_queries": [
{"text": "Nsync popularity", "generation_id": "d9c91674-a27e-493e-954c-7393dc896c5d"},
{"text": "Backstreet Boys popularity", "generation_id": "d9c91674-a27e-493e-954c-7393dc896c5d"}
],
"search_results": [
{"search_query": {"text": "Nsync popularity", "generation_id": "d9c91674-a27e-493e-954c-7393dc896c5d"}, "document_ids": ["web-search_9:25", "web-search_9:26", "web-search_9:27"], "connector": {"id": "web-search"}},
{"search_query": {"text": "Backstreet Boys popularity", "generation_id": "d9c91674-a27e-493e-954c-7393dc896c5d"}, "document_ids": ["web-search_10:0", "web-search_11:0", "web-search_13:3", "web-search_18:2"], "connector": {"id": "web-search"}}
],
"citations": [
{"start": 4, "end": 19, "text": "Backstreet Boys", "document_ids": ["web-search_13:3", "web-search_11:0", "web-search_18:2"]},
{"start": 35, "end": 64, "text": "100 million records worldwide", "document_ids": ["web-search_10:0", "web-search_13:3", "web-search_11:0", "web-search_18:2"]},
//...
],
"documents": [
{"id": "web-search_13:3", "snippet": " The Backstreet Boys have sold over 150 million records worldwide, making them the best-selling boy band of all time, and one of the world's best-selling music artists. They are the first group since Led Zeppelin to have their first ten albums reach the top 10 on the Billboard 200, and the only boy band to do so. The albums Backstreet Boys and Millennium were both certified diamond by the Recording Industry Association of America (RIAA), making them one of the few bands to have multiple diamond albums. The group received a star on the Hollywood Walk of Fame on April 22, 2013. They also released their first documentary movie, titled Backstreet Boys: Show 'Em What You're Made Of in January 2015. In March 2017, the group began a residency in Las Vegas that lasted two years, titled Backstreet Boys: Larger Than Life and ended up being the fastest selling residency in Vegas history.", "title": "Backstreet Boys Biography, Discography, Chart History @ Top40-Charts.com - New Songs & Videos from 49 Top 20 & Top 40 Music Charts from 30 Countries", "url": "https://top40-charts.com/artist.php?aid=137"},
{"id": "web-search_11:0", "snippet": "The discography of American pop vocal group Backstreet Boys consists of ten studio albums, 31 singles, one live album, three compilation albums and 33 music videos. As of 2019, they have sold more than 130 million records worldwide, becoming the best-selling boy band of all time. Formed in Orlando, Florida in 1993, the group consists of Nick Carter, Brian Littrell, Kevin Richardson, A.J. McLean and Howie Dorough. Richardson left the group in 2006 to pursue other interests, but rejoined in 2012. The Backstreet Boys released their debut single \"We've Got It Goin' On\" in 1995, which peaked at number sixty-nine on the Billboard Hot 100. The single, however, entered the top ten in many European countries.", "title": "Backstreet Boys discography - Wikipedia", "url": "https://en.wikipedia.org/wiki/Backstreet_Boys_discography"},
//...
]
}
In addition to the Cohere provided web-search Connector, you can register your own custom Connectors such as Google Drive, Confluence etc.
Prompt Truncation
LLMs come with limitations; specifically, they can only handle so much text as input. This means that you will often need to figure out which document sections and chat history elements to keep, and which ones to omit.
For more information, check out our dedicated doc on prompt truncation.
Caveats
It’s worth underscoring that RAG does not guarantee accuracy. It involves giving a model context which informs its replies, but if the provided documents are themselves out-of-date, inaccurate, or biased, whatever the model generates might be as well. What’s more, RAG doesn’t guarantee that a model won’t hallucinate. It greatly reduces the risk, but doesn’t necessarily eliminate it altogether. This is why we put an emphasis on including inline citations, which allow users to verify the information.
Updated about 1 month ago