Topic Modeling System for AI Papers
Natural Language Processing (NLP) is a key area of machine learning focused on analyzing and understanding text data. One popular NLP application is topic modeling, which uses unsupervised learning and clustering algorithms to group similar texts and extract underlying topics from document collections. This approach enables automatic document organization, efficient information retrieval, and content filtering.
Here, you’ll learn how to use Cohere’s NLP tools to perform semantic search and clustering of AI Papers, which could help you discover trends in AI. You’ll:
- Scrape the most recent page of the ArXiv page for AI, with the output being a list of recently published AI papers.
- Use Cohere’s Embed Endpoint to generate word embeddings using your list of AI papers.
- Visualize the embeddings and proceed to perform topic modeling.
- Use a tool to find the papers most relevant to a query you provide.
To follow along with this tutorial, you need to be familiar with Python and have python version 3.6+ installed, and you’ll need to have a Cohere account. Everything that follows can be tested with a Google Colab notebook.
First, you need to install the python dependencies required to run the project. Use pip to install them using the command below.
And we’ll also initialize the Cohere client.
With that done, we’ll import the required libraries to make web requests, process the web content, and perform our topic-modeling functions.
Next, make an HTTP request to the source website that has an archive of the AI papers.
Setting up the Functions We Need
In this section, we’ll walk through some of the Python code we’ll need for our topic modeling project.
Getting and Processing ArXiv Papers.
This make_raw_df function scrapes paper data from a given URL, pulling out titles and abstracts. It uses BeautifulSoup to parse the HTML content, extracting titles from elements with class "list-title mathjax" and abstracts from paragraph elements with class "mathjax". Finally, it organizes this data into a pandas dataframe with two columns - “titles” and “texts” - where each row represents the information from a single paper.
Generating embeddings
Word embedding is a technique for learning a numerical representation of words. You can use these embeddings to:
• Cluster large amounts of text
• Match a query with other similar sentences
• Perform classification tasks like sentiment classification
All of which we will do today.
Cohere’s platform provides an Embed endpoint that returns text embeddings. An embedding is a list of floating-point numbers, and it captures the semantic meaning of the represented text. Models used to create these embeddings are available in several; small models are faster while large models offer better performance.
In the get_embeddings, make_clusters, and create_cluster_names functions defined below, we’ll generate embeddings from the papers, use principal component analysis to create axes for later plotting efforts, use KMeans clustering to group the embedded papers into broad topics, and create a ‘short name’ that captures the essence of each cluster. This short name will make our Altair plot easier to read.
Get Topic Essences
Then, the get_essence function calls out to a Cohere Command endpoint to create an ‘essentialized’ description of the papers in a given cluster. Like the ‘short names’ from above this will improve the readibility of our plot, because otherwise it would be of limited use.
Generating a Topic Plot
Finally, this generate_chart ties together the processing we’ve defined so far to create a beautiful Altair chart displaying the papers in our topics.
Calling the Functions
Since we’ve defined our logic in the functions above, we now need only to call them in order.
Your chart will look different, but it should be similar to this one:
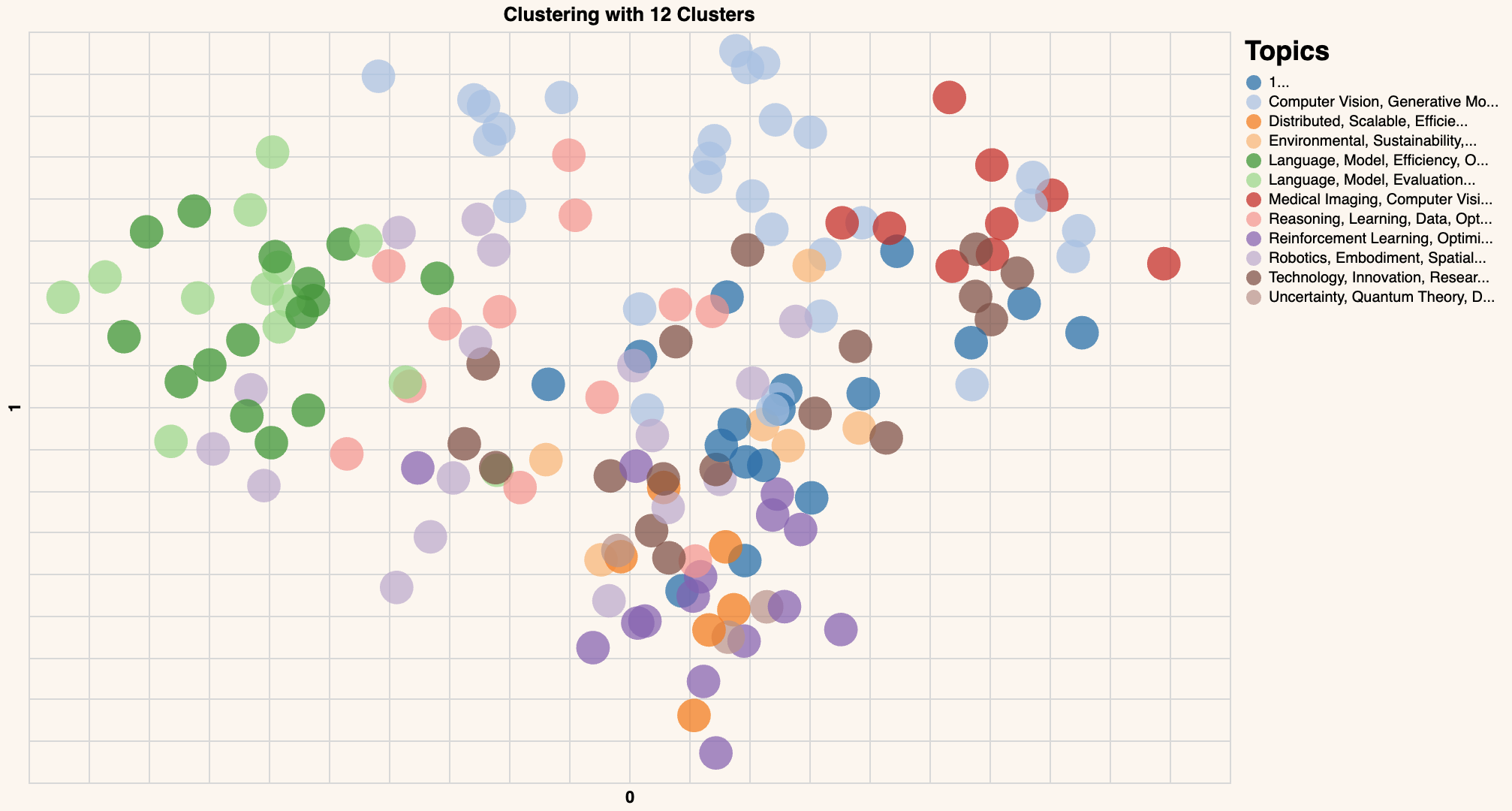
Congratulations! You have created the word embeddings and visualized them using a scatter plot, showing the overall structure of these papers.
Similarity Search Across Papers
Next, we’ll expand on the functionality we’ve built so far to make it possible to find papers related to a user-provided query.
As before, we’ll begin by defining our get_similarity function. It takes a target query and compares it to candidates to return the most relevant papers.
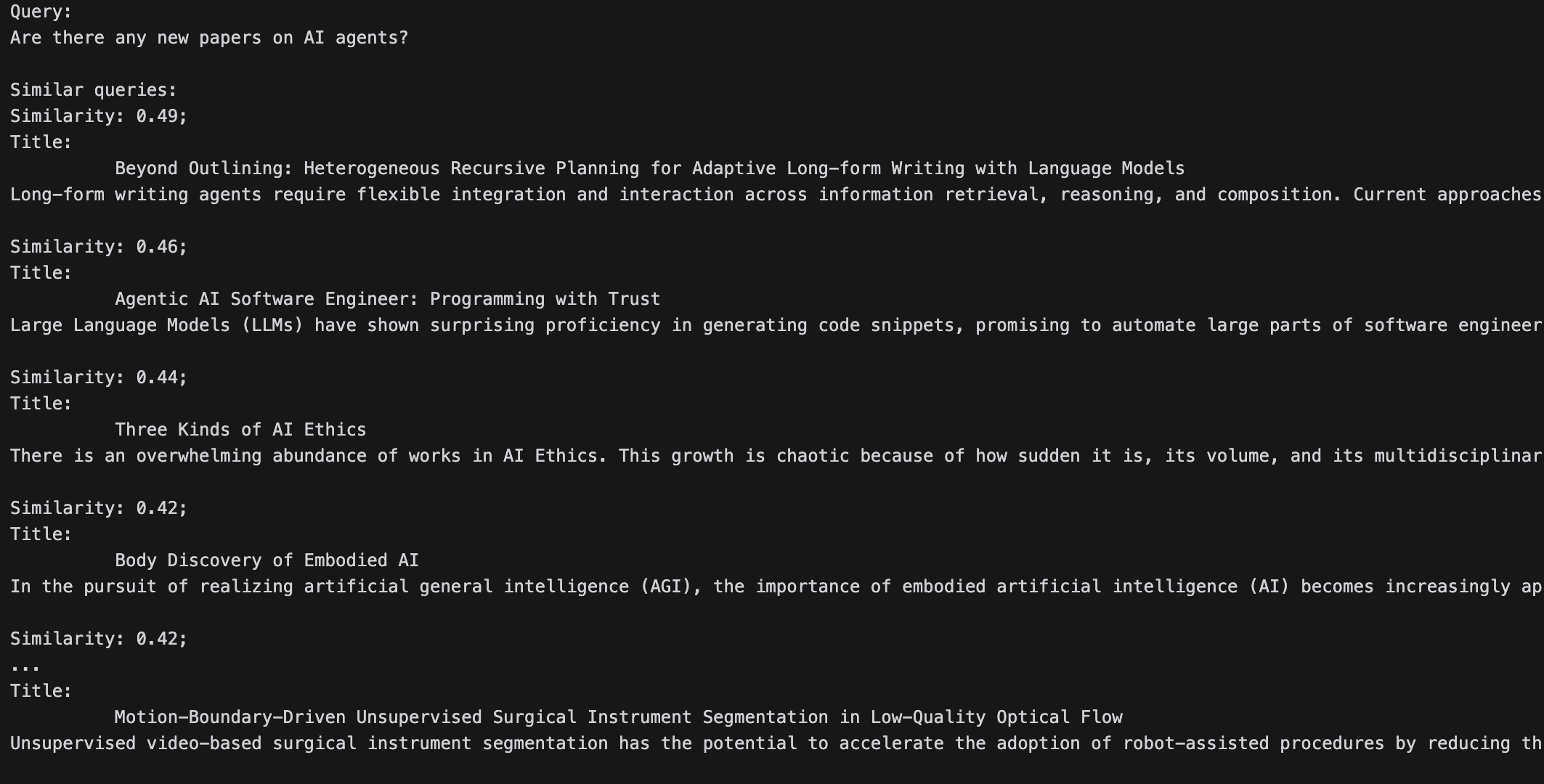
All we need now is to feed it a query and print out the top papers:
You should see something like this:
Conclusion
Let’s recap the NLP tasks implemented in this tutorial. You’ve created word embeddings, clustered those, and visualized them, then performed a semantic search to find similar papers. Cohere’s platform provides NLP tools that are easy and intuitive to integrate. You can create digital experiences that support powerful NLP capabilities like text clustering. It’s easy to register a Cohere account and get to an API key.