The Generate Endpoint
In the previous two chapters, we looked at how we can use the Playground to experiment with ideas in text generation. And let’s say we have now found that idea which we want to build on, so what’s next? In this chapter, we will begin our exploration of the Cohere Generate endpoint, one of the endpoints available from the Cohere API. We’ll move from the Playground to code, in this case via the Python SDK, and learn how to use the endpoint.
Colab Notebook
This article comes with a Google Colaboratory notebook for reference.
Here’s a quick look at how to generate a piece of text via the endpoint. It’s quite straightforward.
We enter a prompt:
And we get a response:
Of course, there are more options available for you to define your call in a more precise way. In this chapter, we will cover that and more, including:
- An overview of the Generate endpoint
- Setting up
- Making the first API call
- Understanding the response
- Turning Playground prompts into code
- Selecting the model
- Understanding the other parameters
- Experimenting with a prompt
But before going further, let’s take a quick step back and reflect on what this all means.
Looking at the code snippet above, it’s easy to miss what’s at play here. There are many options out there for leveraging large language models (LLMs), from building your own models to deploying available pre-trained models. But with a managed LLM platform like Cohere, what you get is a simple interface to language technology via easy-to-use endpoints.
What this means is that you are free to focus solely on building applications instead of having to worry about getting the underlying technology to work. You don’t have to worry about the complexities, resources, and expertise required to build, train, deploy, and maintain these AI models.
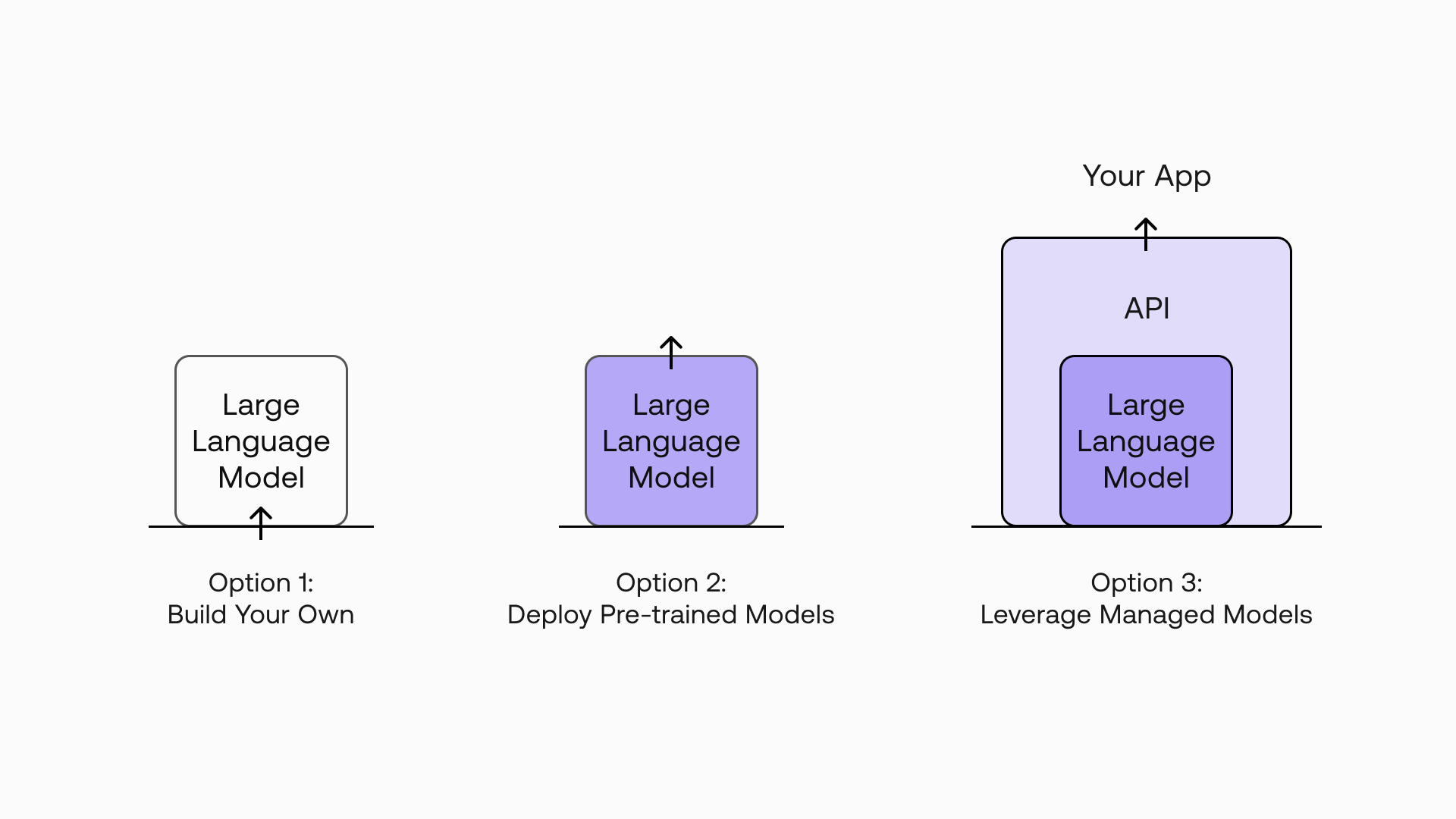
Now let’s dive deeper into the Generate endpoint.
Overview of the Generate Endpoint
The Cohere platform can be accessed via the Playground and SDK. In this article, we’ll learn how to work with the Python SDK.
With the API, you can access a number of endpoints, such as Generate, Embed, and Classify. Different endpoints are used for different purposes and produce different outputs. For example, you would use the Classify endpoint when you want to perform text classification.
Our focus for this series is, of course, text generation, so we’ll work with the Generate endpoint.
Setting Up
First, if you haven’t done so already, you can register for a Cohere account and get a trial API key, which is free to use. There is no credit or time limit associated with a trial key but API calls are rate-limited. Read more about using trial keys in our documentation.
Next, you need to install the Python SDK. You can install the package with this command:
Making the First API Call
Now, to get a feel of what the Generate endpoint does, let’s try it with the code snippet we saw earlier.
Import the Cohere package, define the Cohere client with the API key, and add the text generation code, like so.
We defined a number of parameters.
model— We selectedcommand.prompt— The prompt, which is an instruction to write a social ad copy.max_tokens— The maximum number of tokens to be generated. One word is about three tokens.
The complete list of parameters can be found on the Generate API Reference page.
Run it on a Python interpreter and you get the response:
And that’s our first API call!
Understanding the Response
Let’s understand what we get from the API response.
The Generate endpoint accepts a text input, that is the prompt, and outputs a Generation object.
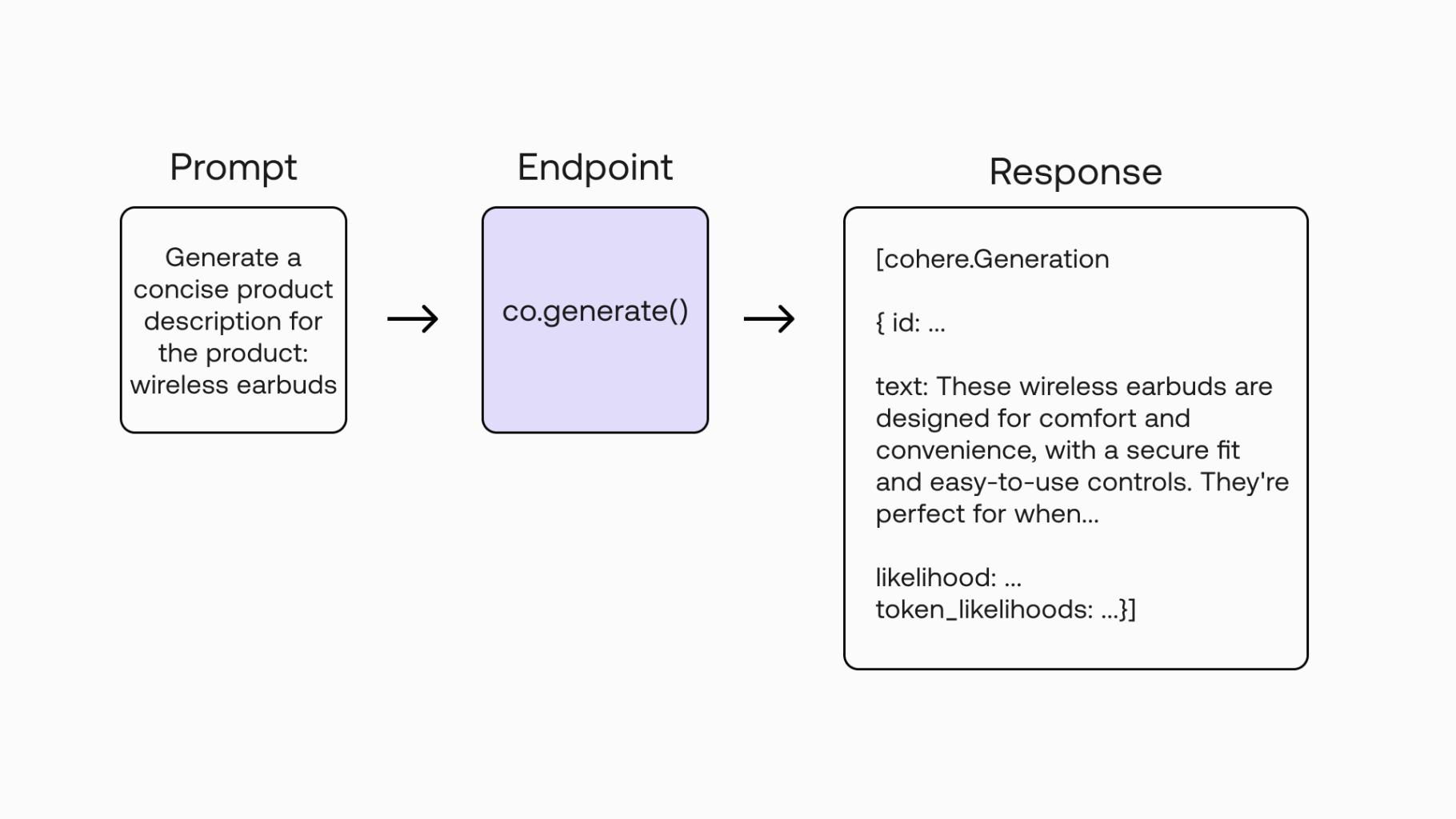
Here’s an example response, with the text generated:
The response contains:
id— A unique ID for the generationprompt— The prompt provided by the usertext— The generated text, given the inputlikelihood— The average likelihood of all generated tokens (one English word roughly translates to 1-2 tokens)token_likelihoods— The likelihood of each token
If you want to keep it simple, you just need to get the text output and you’re good to go, like what we have done so far: response.generations[0].text. Here, we defined the index of the generation (index 0, representing the first item) because the endpoint can actually generate more than one output in one go. We’ll cover how to get multiple generations later in this article.
In some scenarios, we may want to evaluate the quality of our output. This is where we can use the likelihood and token_likelihoods outputs.
We covered what likelihood is in the Prompt Engineering chapter. Now let’s look at an example to understand likelihood and token_likelihoods.
Say our text input is, “It’s great to” and the generated text is, “be out here”. These three output words map directly to three individual tokens, which we can check using the Tokenize endpoint.
Response:
So, back to the Generate endpoint output, let’s say we get the following likelihood values for each token:
be: - 2.3out: -0.3here: -1.2

So, the average likelihood of all generated tokens, in this case, is the average of the three tokens, which equals -1.3.
Note that you need to enable the return_likelihoods parameter to return either GENERATION (output only) or ALL (output and prompt), otherwise, you will get None for the likelihood and token_likelihoods outputs.
Response:
Turning Playground Prompts into Code
Recall that in the previous chapter, we went through a number of prompt ideas, where each comes with its own preset link. You might have come up with some ideas and saved them as presets. The question is, how do you turn those into code?
It’s easy. If you go back to the Playground and open up a preset, you will see a View Code button on the top right. Click on that button and you will get the code version of that preset in the language of your choice (the screenshot below shows a Python example).
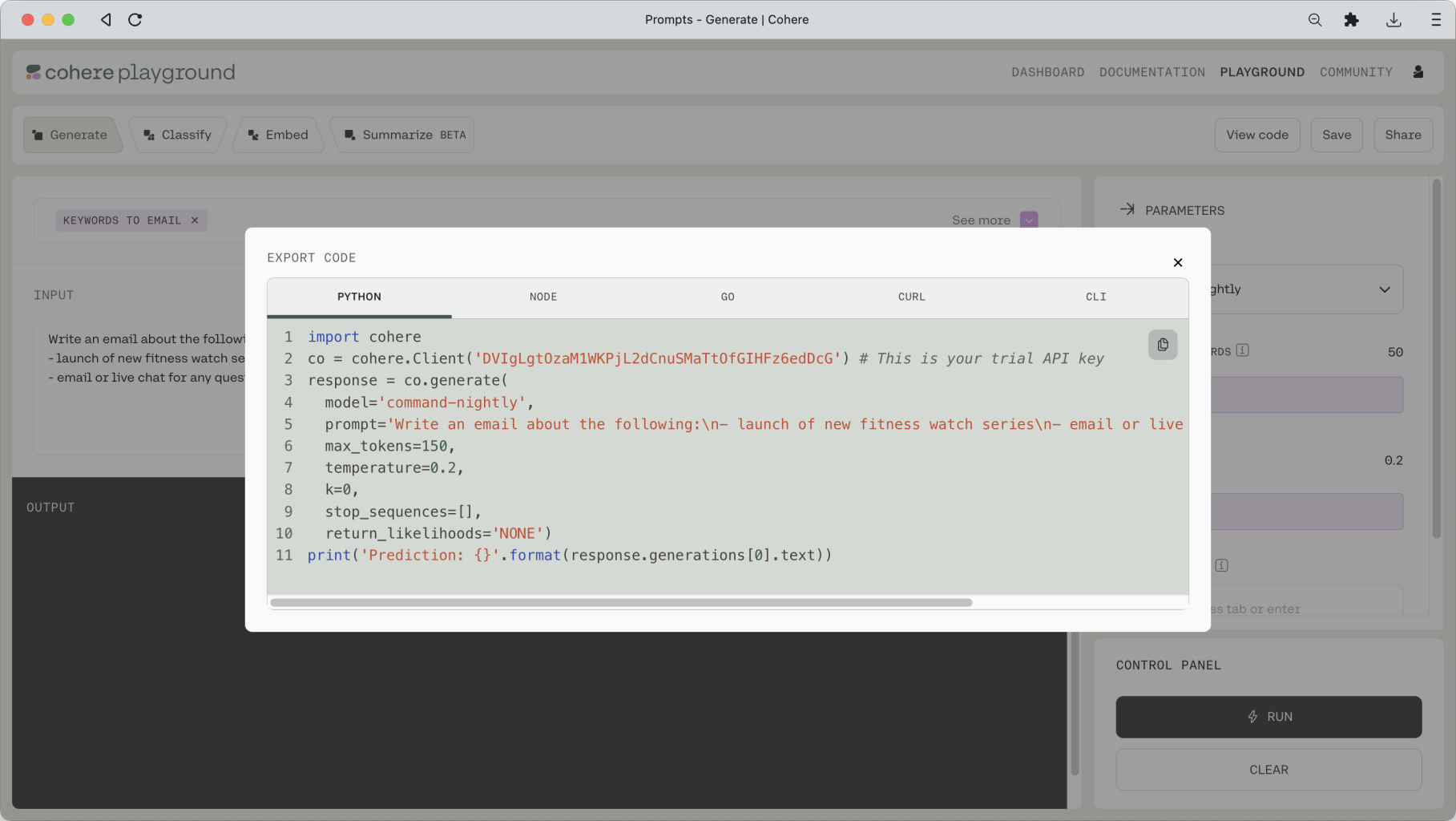
You can simply copy and paste this code into the Python interpreter to get the response.
Selecting the Model
We have only used one model so far: command. But there are a few other types of models available with the endpoint. Here are the available models at the time of writing:
- Default versions:
commandandcommand-light - Experimental versions:
command-light-nightly
The presence of the term light in the names represent models with smaller parameter sizes. So, which one do you choose? It depends on your use case, but as a rule of thumb, smaller models are faster, while larger models are generally more fluent and coherent.
Understanding the Other Parameters
While defining just the model is enough to get started, in reality, you will likely need to specify other parameters as well, so the model’s output will match your intended output as closely as possible.
We covered some of these parameters in the model prompting chapter but not the exhaustive list. So, now is probably a good time to visit the Generate endpoint docs and learn more about all the available parameters, for example, their default values, their value ranges, and more.
Experimenting with a Prompt
If you have a prompt idea that you really want to take to the next step, you may want to experiment extensively with it, for example, by trying out different parameter combinations and finding that ideal combination that fits your needs.
You can do that with the Playground, but since you’ll have to manually adjust the settings after each generation, it’s probably not going to be very efficient. That’s when the SDK comes in.
In the following example, we’ll take a prompt (product description) and create a small function to automatically iterate over different text generations. This way we can evaluate the generations in a much faster way.
In particular, we’re going to use the following parameters:
temperature(same asRANDOMNESSin the Playground)— we’ll iterate over a range of values to arrive at a value that fits our use casenum_generations— we can use this parameter to get five generations in one go instead of onereturn_likelihoods— we’ll set this to GENERATIONS and use this to evaluate the randomness of our text output

And here’s what the code looks like:
You can run the code in the notebook and get the full generation. Here, we are showing a few example outputs, as the full generation is quite long (view the notebook to see the full generation).
Conclusion
In this blog post, we made our first foray into the Generate endpoint using the Python SDK. We got familiarized with how to get text generations via the API, and we created a simple function to help us experiment with a prompt idea.
We have only covered the basics, though. In upcoming articles, we’ll look at how we can integrate the endpoint into proper applications, such as adding user interfaces, working with other endpoints in tandem, and more.
Original source
This material comes from the post Generative AI with Cohere: Part 3 - The Generate Endpoint.